SCSKでは、Dropbox導入案件の多くで、オンプレファイルサーバやNASなどからDropboxにデータ移行のお手伝いをさせていただいております。近年、弊社がデータ移行する際はDropbox社が推奨するMovebotというデータ移行ツールを利用することがほとんどです。
ちょっと脱線 – Dropboxへのデータ移行方法
本題に入る前に、少しDropboxへのデータ移行方法についてお話したいと思います。
筆者が初めてDropboxへのデータ移行案件に関わった2018年頃の話です。
まだDropboxへのデータ移行ツールが存在せず(という記憶があります)、Dropboxデスクトップクライアントのデータ同期機能を使って移行するしか方法がありませんでした。ただ、この方法にはいくつか大きな課題がありました。
Dropboxデスクトップクライアントでのデータ移行って大変なんです
課題をまとめると次の3点です
- PCのローカルストレージ容量問題です
- Dropboxデスクトップクライアントの最大同期数の問題です
- データ同期の結果を確認することができないことです
このように、Dropboxデスクトップクライアントを使ったデータ移行は、PCストレージ容量と同期ファイルサイズに大きく影響され、100GB以下の小規模なデータ移行までが限界という感じです。Dropbox導入企業様自身でデータ移行するには良い方法かもしれませんが、ファイルサーバのような大規模データ移行には向いてません。
Movebotは…
冒頭でお話したとおり、近年弊社ではDropbox導入案件のデータ移行作業において、Movebotを受かってデータ移行を行っています。その主な理由は、下記の3点です。
- Movebotは、データ移行に用いるPCのローカルストレージを利用しないこと (ストレージ容量の影響を受けない)
- WEB画面からリモート操作ができること
- データ移行ログが充実していること
特に、1. のPCローカルストレージの容量に影響しない仕組みのため、大容量のデータ移行に向いたツールです。
ただ、Movebotにもデメリットはあります。Movebotはデータ転送容量課金ですので、データ移行容量によってはデータ移行コストが高くなってしまいがちです。データ移行作業に回せる予算が少ないと、Movebotの採用は難しい場合も…。
Movebotについては、別のブログ記事で詳しくご紹介していますので、そちらもご覧ください。
Dropbox APIによるデータ移行ツール!
Movebotのように、PCストレージ容量に影響を受けないようにするには、ファイルサーバから読み取ったデータを直接Dropboxにアップロードする必要があります。これを実現するのが、Dropbox社が公開しているDropbox APIです。
Dropbox APIにはたくさんの機能エンドポイントが用意されていますが、その中にファイルアップロードするためのAPIも含まれています。これを使ったデータ移行ツールを開発し、お客様自身で比較的簡単にデータ移行できるようなにツールを提供できれば、喜んでいただけるのではないか。そうして開発したのが sxtool です (GUI付き版が 「セルフデータ移行ツール」となります) 。弊社自身、気楽に使えるデータ移行ツールが必要だったというのも理由の一つですが…。
それでは、Dropbox APIを使ったデータ移行処理について詳しくご紹介したいと思います。
Dropbox APIを使ったデータ移行処理
データ移行処理って?
ファイルサーバのデータをDropboxに移行するには、下記のようにファイルサーバからファイルのデータを読み込み、Dropbox APIを使ってDropboxに書き込むことで実現できます。
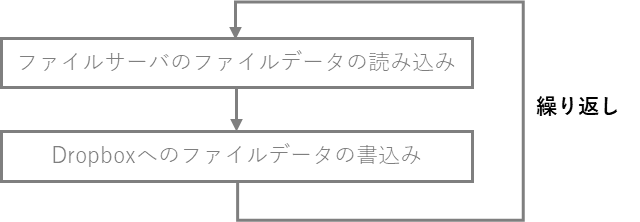
図1: データ移行ロジック
ファイルサーバのファイル読み込みは、開発言語に用意されているファイルI/Oのライブラリ(関数)を利用すれば簡単に実装できます。Python だと、下記のようにopen関数やread関数を使います。
with open(path, 'rb') as f: # path変数で指定したパスのファイルを開く
data = f.read() # データ読み込み処理
Dropbox へのファイルアップロード
Dropboxに読み込んだファイルデータを書き込む(アップロード)には、Dropbox APIの upload エンドポイントを使用します。下図は、Dropbox開発向けサイトの upload エンドポイントのマニュアルを抜粋したものです。(出典: HTTP – Developers – Dropbox)
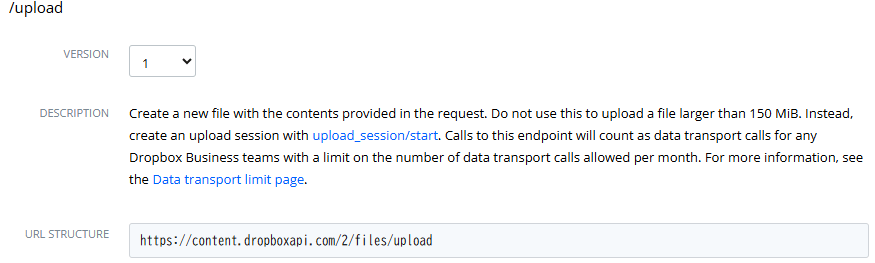
図2: uploadエンドポイントマニュアル(抜粋)
上記マニュアルに記載されてるように、upload エンドポイントは、Dropbopxでのファイルパスや書込みモードなど、いくつかのパラメータと(読み込んでおいた)ファイルのバイナリデータを指定し、Dropboxにアップロードします。
upload エンドポイントのパラメータ:
- path: ファイルパス
- mode: 書込みモード (追加(add) / 上書き(overwrite) / 更新(update))
- autorename: 自動でファイル名を変える (上書きせず、番号をつける)
- mute: 通知をする/しない
- client_modified: 移行元のファイルタイムスタンプを指定 (更新タイムスタンを保持できる)
など
pythonでDropboxにファイルアップロードする処理を実装すると、下記のようになります。
with open(path, 'rb') as f: # path変数で指定したパスのファイルを開く
data = f.read() # 移行元のデータを読み込み
url = 'https://content.dropboxapi.com/2/files/upload'
param = { # upload エンドポイントのパラメータを指定
"path": path,
"mode": mode,
"autorename": False,
"client_modified": source_file_timestamp,
"mute": False,
"strict_conflict": False
}
headers = {
"Authorization": "Bearer " + oauth_token,
"Content-Type": "application/octet-stream",
"Dropbox-API-Arg": json.dumps(param),
}
response = requests.post(url, headers=headers, data=data) # APIコール
このコードを実際に動かすには、Dropboxの認証情報である OAUTH_TOKEN を事前に取得し、”oauth_token” 変数に代入するか、oauth_token 部分を OAUTH_TOKEN文字列に置き換える必要があります。また、他にも、uploadエンドポイントの結果確認処理や例外処理など実現すべき点はたくさんあります。
フォルダ単位のデータ移行
1ファイルのみアップロードする処理は、先程ご紹介したとおりです。この処理を移行元フォルダ配下の全ファイル分繰り返し実施すれば、フォルダ単位の「データ移行」が実現できます。移行元フォルダにサブフォルダが存在した場合、サブフォルダの作成処理とサブフォルダの移行処理(フォルダ単位の移行処理を再帰的に呼び出す)を実施します。
これをチャートにすると、ざっくり下図のようになります。
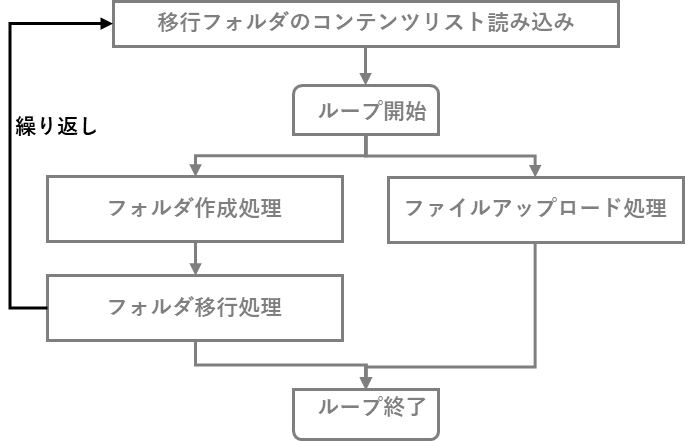
図3: データ移行ロジック2
この仕組みでデータ移行すると、1ファイルずつファイルサーバから読み込んでは、Dropboxにアップロードすることになります。要は、シーケンシャルに1ファイルずつしか移行できないわけです。
例えば、1MBのファイルを1つアップロードするのに、0.2 秒掛かると仮定すると、1MB x 1万ファイルのデータ移行に 約 33 分掛かります。
式) 0.2 秒 x 10,000 = 2,000 秒 ≒ 33分
このときのデータ転送速度は 5MB/sec です。
式) 1MB x 10,000 ÷ 2,000 秒 = 5 MB/sec
ネットワーク帯域が 1Gbps (=125MB/sec) の回線だと仮定すると、データ移行ではネットワーク帯域を少ししか使っていないことになりますね。ネットワーク帯域の1Gbpsという数値は理論値なので 実際には理論値の 5~6割程度が利用可能な帯域だとしても、帯域の 1/10 くらいしか使っていませんね。ネットワーク帯域をすべて使い切ってしまうと他の業務に影響がでるため好ましくありませんが、業務に影響が出ない範囲でデータ移行が利用する帯域を増やして、移行時間を短縮する必要があります。
データ移行の並列化
さて、ネットワーク帯域をもっと有効活用するにはどうすればいいでしょうか?
そうです、Dropboxサーバへのファイルアップロード処理を何個も同時実行すればいいのです。
例えば、4ファイル同時にアップロードできれば、5MB/sec x 4 = 20 MB/sec の帯域を使いますが、4ファイル順番に移行するよりも単純計算で移行時間が 1/4 になります。1万ファイルの移行時間もたったの 8分ちょっとに短縮できちゃいます。ファイルアップロードの並列化は移行時間の短縮にとても効果がありそうです。
APIコール数の削減
また、APIコール数の削減も移行時間の短縮に効果があります。
Dropbox APIの処理時間は「リクエスト送信 +サーバでの処理+レスポンス受信」の合計となります。例えば リクエスト送信 0.2秒、サーバサイド処理 0.3 秒、レスポンス受信 0.2 秒 と仮定すると、1 APIコールの処理時間の合計が 0.7 秒。「リクエスト送信」と「レスポンス受信」で 0.4 秒。「サーバサイド処理」が 0.3 秒 ですので、「リクエスト送信とレスポンス受信」の処理時間のほうが「サーバサイトの処理」よりも長くなってしまっていますね。
Dropboxのデータ移行先サブフォルダを作成する場面で計算してみましょう。
移行元には500個のサブフォルダが存在するとします。1サブフォルダずつフォルダ作成を行うとすると、create_folder エンドポイントを 500 回コールすることになります。これだけで、350秒 (約 6 分) もかかっちゃいます。
式) 500 x 0.7 秒 = 350 秒 (約 6 分)
1回のサブフォルダ作成リクエストで複数のサブフォルダをまとめて作成できると、APIコール数を削減できますね。1リクエストで 500個作成できるとすると、499 x 0.4秒(リクエスト+レスポンスの時間) ≒ 200秒 (約 3.5分) の短縮になります。
データアップロードの並列化とAPIコール数を削減するAPI
Dropbox APIには、「ファイルアップロード処理の並列化」と「APIコール数の削減」ができるエンドポイントも用意されています。それが create_folder_batch エンドポイントと upload_session エンドポイント群です。
まとめてフォルダ作成エンドポイント
- create_folder_batch と create_folder_batch/check
create_folder_batch エンドポイントを利用すると、Dropboxサーバに複数のフォルダ作成を依頼できます。最大 1000フォルダ分を1リクエストのパラメータに指定できます。サーバサイドの処理が非同期処理になった場合は、終了待ちを行う create_folder_batch/checkエンドポイントで処理完了の待ち合わせを行うことが可能です。
ファイルアップロード並列化エンドポイント
- upload_session/start
Dropboxサーバにファイルデータ送信のセッションを作成するためのエンドポイント。このエンドポイントと次の append エンドポイントを利用して、ファイルデータ送信を行います。ファイルアップロード処理の完了は、upload_session/finish エンドポイントを使います。
- upload_session/append
upload_sessoin/start で作成したファイルデータ送信用セッションを使って、ファイルデータをアップロードできます。何度も append エンドポイントを繰り返し利用することで、大きなファイルをアップロードすることも可能です。
ファイルメタデータまとめてエンドポイント
弊社が開発したデータ移行ツールでは、これらのエンドポイントを駆使して、データ移行時間の短縮を図っています。データ移行のロジックも図4のようにサブフォルダの作成処理、ファイルアップロード処理に分割し、おまとめエンドポイントの利用と並列化を実現しやすいように変えています。
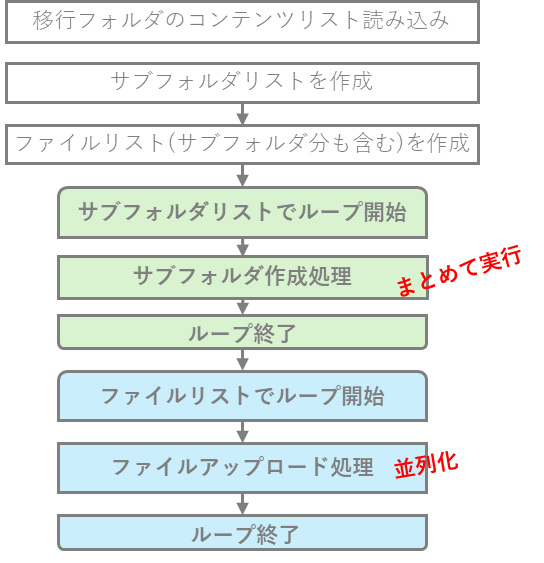
図4: 改良版データ移行ロジック
これにより、サブフォルダの作成をまとめることができ、最大1000個のサブフォルダを1回のAPIコールで済ますことができます。サーバサイドの処理時間は変わらないとしても、リクエスト送信+レスポンス受信 の時間 1,000回分を 1回分だけに削減できます。
また、ファイルアップロード処理は、upload_session/start + upload_session/append を用い、並列してファイルデータをアップロードすることでデータ移行時間を短縮します。
upload_sessionエンドポイントのもうひとつのメリット
upload_sessionエンドポイントを利用する、メリットがもうひとつあります。
uploadエンドポイントでは、最大 150MB までしかアップロードできないという制限があります。ということは、150MBより大きなファイルはDropboxにアップロードできないということになってしまうのですが、その制限をクリアするのが upload_session エンドポイントなのです。
upload_session/start や upload_sessoin/append も 1コールで指定できるファイルデータサイズは最大 150MB と upload エンドポイントと変わりないのですが、元のファイルを 150MB単位でブロック化し、upload_session/append エンドポイントで追加ブロック分を繰り返し送信することで、最大 2TB までアップロードできるようになっています。
ファイルサイズが 150MB 以下だと、upload_session/start と append, finish の 3つのエンドポイントを使ってファイルアップロードすることになるため、uploadエンドポイントより不利な面がありますが、finish_batch を使えばAPIコール数の削減も実現できますし、大きなファイルを送信できるという点で upload_session 系エンドポイントを利用する価値があります。
upload_sessoin系エンドポイントのサンプルコード
upload_sessionエンドポイントを使った簡単なサンプルコードを紹介します。
まずは、ファイルデータの送信部分です。
下記のサンプルコードは、1ファイル分のファイルデータをアップロードする処理です。upload_session/start ではファイルデータを添付せず、ファイルデータのアップロードはすべて upload_sessoin/append で行っています。
with open(source_path, 'rb') as f:
offset = 0
if <移行元ファイルサイズ> == 0:
flag_close = True
else:
flag_close = False
# upload session開始
url = "https://content.dropboxapi.com/2/files/upload_session/start"
param = {
"close": flag_close
}
headers = {
"Authorization": "Bearer " + oauth_token,
"Content-Type": "application/octet-stream",
"Dropbox-API-Arg": json.dumps(param),
}
response = requests.post(url, headers=headers, data="") # APIコール
response_json = response.json()
session_id = response_json["session_id"]
# ファイルデータは upload_session/append で送信
while True:
chunk = f.read(UPLOAD_CHUNK_SIZE) # UPLOAD_CHUNK_SIZE は 150MB
if len(chunk) > 0:
if len(chunk) < UPLOAD_CHUNK_SIZE: # 詠み込んだ量が 150MB 以下ならこの append で終わり
flag_close = True
else:
flag_close = False
url = "https://content.dropboxapi.com/2/files/upload_session/append_v2"
param = {
"cursor": {
"session_id": session_id,
"offset": offset
},
"close": flag_close
}
headers = {
"Authorization": "Bearer " + oauth_token,
"Dropbox-API-Arg": json.dumps(param),
"Content-Type": "application/octet-stream",
}
response = requests.post(url, headers=headers, data=chunk) # APIコール
offset += len(chunk)
この処理を並列実行できるように関数化し、ファイル単位でプロセスを分けることで並列実行を実現します。
ファイルメタデータの書込み処理は、上記のファイルデータのアップロードセッション 1,000個分をまとめて finish_batch を使うため、ファイルデータアップロード部分と分離しておきます。
upload_session/finish_batch を使ったメタデータ書込み処理
entries = []
# session_ids = データアップロードのセッションIDリスト
for session_id in session_ids:
entry = {
"cursor": {
"session_id": session_id, # ファイルアップロード時の session_id (session_ids リストで保存しておく)
"offset": offset # ファイルアップロード時の offset値 (session_ids リストで保存しておく)
},
"commit": {
"path": target_path, # session_ids リストで保存しておいた移行先パス
"mode": mode,
"autorename": False,
"client_modified": client_modified, # session_ids リストで保存しておいた移行元ファイルタイムスタンプ
"mute": False,
"strict_conflict": False
}
}
entries.append(entry)
# APIコール部分
url = "https://api.dropboxapi.com/2/files/upload_session/finish_batch_v2"
headers = {
"Authorization": "Bearer " + oauth_token,
"Content-Type": "application/json",
}
data = {
"entries": entries
}
response = requests.post(url, headers=headers, data=data) # APIコール
# このあと
# finish_batch がバックグランドジョブになった場合は、upload_session/finish_batch/check で定期的に終了確認を行う
おわりに
今回は前編ということで、データ移行に関係する Dropbox API の紹介と弊社が開発したデータ移行ツールの処理ロジック、サンプルコードをご紹介を致しました。
後編では、並列化の効果や他の機能や工夫点などをご紹介する予定にしています。
SCSKでは、お客様のご要件に合わせたDropbox APIツールの開発も行っております。Dropbox運用の効率化や棚卸しなどでツールがほしい!といったご要望があれば、是非 SCSKまでご遠絡頂けたらと思います。

