
こんにちは。SCSKの磯野です。
Google Cloudにおける監視は、ログ監視とメトリクス監視の2種類に分けることができます。
今回は、それぞれの監視方法についてご説明します。
ログ監視 – Cloud Logging
Google Cloudにおけるログの収集・保管・管理はCloud Loggingで行います。
Cloud Loggingとは
各 Google Cloud サービスが出力するログは自動的に Cloud Logging に集約されます。主な機能は以下の通りです。
- ログバケット(GCSとは別物。Cloud Logging専用のストレージ)にログが保管される。 以下2つのバケットがデフォルトで存在。
- _Required
Google Cloud が必須で取得する監査系のログが投入される、無料。 - _Default
_Required以外のすべてのログが格納される。デフォルトでは保持期間が30日。 30日までなら保持期間無料。$0.50 / GiB の取り込み(保存)料金は発生する
- _Required
- ログエクスプローラー:ログバケットに格納されているログを閲覧可能
- Log Analytics:ログバケットに格納されているログをSQLでクエリ可能
ログ監視
Cloud Monitoring でアラートポリシーの条件を設定します。アラートポリシーの作成方法には3種類あります。
- ログベースの指標(メトリクス)
「ログでErrorという文字列を5分間で3個以上検知したらメール通知する」というような、指標をモニタリングするアラートポリシーを作成するイメージ。 昔はこちらしかなかった。ログベースのアラートと異なり、複数のログを集約して検知することが可能。 - ログベースのアラート
検知対象の文字列を指定してログベースのアラートを設定する。 - SQLベースのアラート
Terraformサンプル
# CloudRunのエラーログが発生したことを検知するアラートポリシー resource "google_monitoring_alert_policy" "cloud_run_warn" { display_name = "Cloud Run - Error Detected" combiner = "OR" conditions { display_name = "Log match - Cloud Run Error" condition_matched_log { filter = <<EOT (resource.type="cloud_function" OR resource.type="cloud_run_revision" OR (resource.type="cloud_run_job" AND protoPayload.serviceName="run.googleapis.com")) AND severity="ERROR" AND ( resource.labels.project_id="xxx" ) EOT label_extractors = { error_message = "EXTRACT(protoPayload.status.message)" } } } enabled = true alert_strategy { notification_prompts = ["OPENED"] notification_rate_limit { period = "300s" # 5分毎の集計 } auto_close = "1800s" # 下部に補足あり } notification_channels = "xxx(通知先のslackなど)" documentation { content = <<EOT project: $${resource.labels.project_id} job name: $${resource.labels.job_name} error_message: $${log.extracted_label.error_message} EOT mime_type = "text/markdown" } }
メトリクス監視 – Cloud Monitoring
Google Cloudにおけるメトリクスの収集・管理はCloud Monitoringで行います。
Cloud Monitoringとは
- 各種 Google Cloud サービスからパフォーマンスデータ等を収集して保存・閲覧可能にするサービス。取得できる指標には以下のような種類がある。
- Google Cloud の指標:デフォルトで収集される指標
Google Cloud metrics | Cloud Monitoring - エージェントの指標:Opsエージェントをインストールすると、メモリ使用率 , ディスク使用率 , スワップ利用率 などを取得できる
Ops Agent metrics | Cloud Monitoring | Google Cloud - カスタム指標
ユーザー定義の指標の概要 | Cloud Monitoring | Google Cloud
- Google Cloud の指標:デフォルトで収集される指標
- メトリクスエクスプローラー:グラフの作成が可能
Metrics Explorer でグラフを作成する | Cloud Monitoring | Google Cloud - アラートのdocumentation・ラベルを活用することで、通知メッセージをカスタマイズすることが可能

メトリクス監視
Cloud Monitoring で設定する
- 指標ベースのアラート
クエリ言語の種類
- MQL:非推奨
Monitoring Query Language overview | Google Cloud - PromQL:推奨
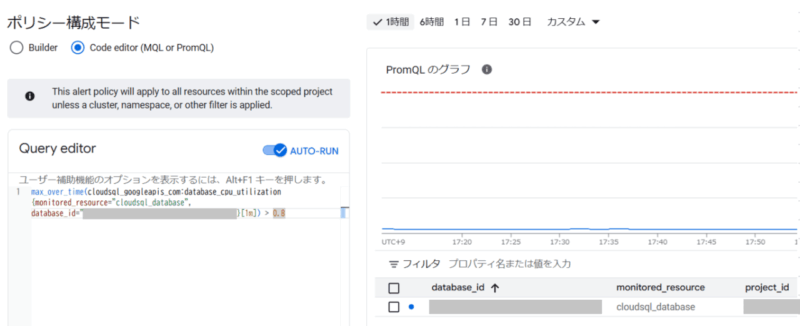
Cloud Monitoring の PromQL | Google Cloud- Cloud Monitoringのアラートポリシー作成画面にて、メトリクスのプレビューが可能
- Builderで作成した場合でも、Metrics Explore経由であればPromQLへの変換が可能
※ただし、__intervalなど一部正確に変換できないケースがあります。ご留意ください - Cloud Monitoring の指標と PromQL のマッピング | Google Cloud
- Cloud Monitoringのアラートポリシー作成画面にて、メトリクスのプレビューが可能
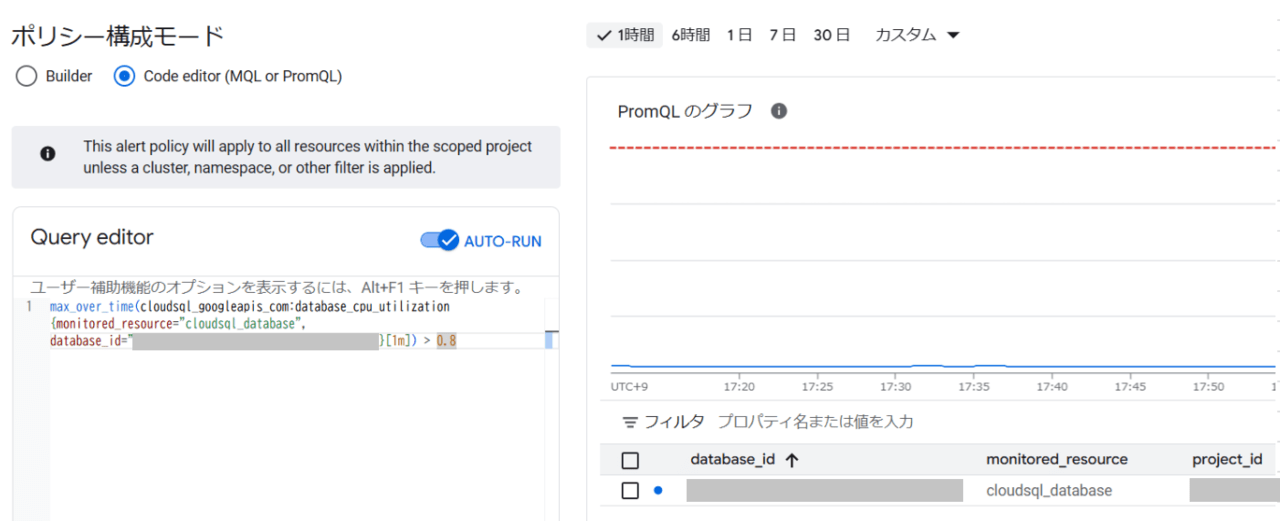
クエリナレッジ
- $__interval:ダッシュボード UI 内で選択される、時刻範囲に基づく間隔を表します。 例えば、この変数を使用して、経時的な比率や平均などのさまざまな操作の時刻範囲を調整することもできます。
PromQL の使用 | IBM Cloud 資料
Terraformサンプル
# VMが停止したことを検知するアラートポリシー。メトリクスが欠損したら発報 resource "google_monitoring_alert_policy" "vm_stoped" { display_name = "VM Instance - Uptime Absent(API VM Stopped)" combiner = "OR" conditions { display_name = "VM Instance - Uptime" condition_prometheus_query_language { query = <<EOT absent(avg by (instance_name, project_id)( increase(compute_googleapis_com:instance_uptime{ monitored_resource="gce_instance", project_id="xxx", instance_name="xxx"}[5m])) ) == 1 EOT duration = "240s" # 最大 240 秒間はデータは表示されないため } } notification_channels = "xxx(通知先のslackなど)" alert_strategy { notification_prompts = ["OPENED"] } documentation { content = <<EOT Project: "xxx" instance_name: "xxx" EOT } }
参考資料
- Terraformドキュメント: Terraform Registry