

LifeKeeperの『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策
こんにちは、SCSKの前田です。
いつも TechHarmony をご覧いただきありがとうございます。
システム基盤の主戦場がオンプレミスからパブリッククラウドへと移り変わり、AWSやAzure上でHAクラスタを構築する機会がぐっと増えました。クラウドでのインフラ設計において、「いかにクラウドリソースを最適化し、コストや構築の手間を抑えるか」は常に重要なテーマです。
そのため、サーバーのNICを最小限に抑えたり、オンプレミスと同じ感覚で同一サブネット内にネットワークをまとめようとしたり、監視用のサーバー(Witness)の台数を節約しようと考えるケースがよく見られます。 しかし、HAクラスターソフトウェアであるLifeKeeperをクラウド(特にAzure環境)で構築する場合、この「オンプレミス感覚のネットワーク設計」や「コストを意識した構成」が、思わぬ構築の壁となって立ちはだかることがあります。仮想IP(VIP)が正常に機能しなかったり、スプリットブレイン対策の構成要件を満たせず、設計の手戻りが発生してしまうのです。
本連載企画「LifeKeeper の『困った』を『できた!』に変える!サポート事例から学ぶトラブルシューティング&再発防止策」では、サポートセンターに蓄積された「生のトラブル事例」を元に、安定運用のための実践的な知恵を共有していきます。
1. はじめに
前回の「カテゴリ3 第1弾」では、AWS環境における自動復旧機能との競合や回避策について解説しました。 第2弾となる今回は、Microsoft Azure(以下、Azure)環境にフォーカスします。
Azure環境での構築・運用において、サポート窓口には「オンプレミスの感覚でIPアドレスやサブネットを設定したら通信ができない!」といったネットワーク周りのご相談や、「スプリットブレイン対策(Quorum)の最適な構成・ディスクの選び方が分からない」というお問い合わせを数多くいただきます。
今回は、Azure環境においてハマりやすい「ネットワーク設計(IP割り当て・内部ロードバランサー連携)」の罠と、スプリットブレインを防ぎつつリソースを最適化するための「Quorum/Witness設計」の正解について、実際のサポート事例を交えて紐解いていきましょう!
💡 前回の記事(カテゴリ3 第1弾)はこちら!
▶【クラウド環境特有の落とし穴 #1】良かれと思った自動復旧が仇に!?AWS環境(EC2/Route53/S3)でハマる構成と回避策 – TechHarmony
2. 今回の「困った!」事例①:IP・ネットワーク設計の落とし穴
❓ 事象の概要(困った!)
「Azure上のWindowsサーバー2台でLifeKeeperを構築予定です。コストや構築の手間を省くため、仮想IPリソースとDataKeeperのミラーリングで利用するNICを『同一サブネット』に配置したいと考えています。ただ、仮想IP自体は別セグメントにする予定ですが、動作やサポート要件に影響はありますか?」
🔍 原因究明のプロセスと判明した根本原因
オンプレミスであれば、柔軟にルーティングやVLANを設定して対応できるケースもありますが、Azure環境ではネットワークの仕組みが異なります。サポートで仕様と要件を確認したところ、Azure環境特有の厳しいルールが判明しました。
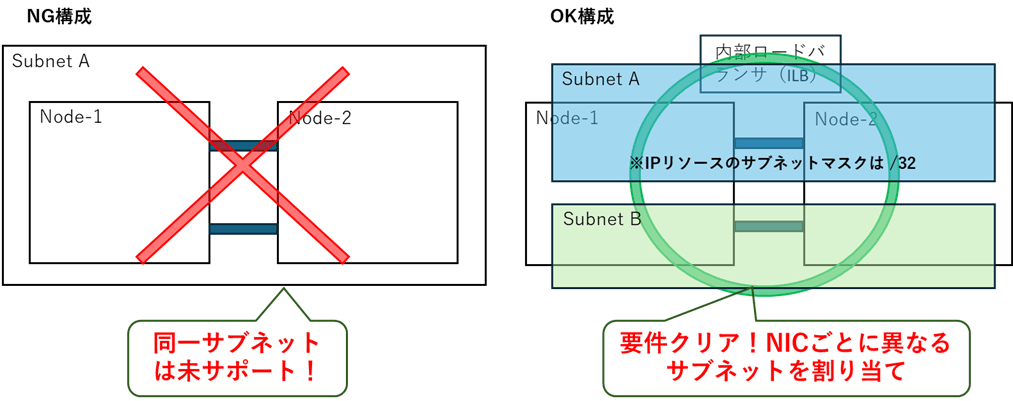
Azure上で仮想IP(VIP)を機能させるためには、ロードバランサー(ILB:内部ロードバランサー等)を用いたネットワーク切り替えが前提となります。この仕組みを正常に動作させるため、LifeKeeperの要件として「保護するNICごとに異なるサブネットを割り当てること」が必須(同一サブネットでの構成は未サポート)となっているのです。
💡 具体的な解決策(できた!)
Azure環境でネットワークを構成する際は、以下の対応を行うことで正常に構築・運用が可能です。
- 異なるサブネットの割り当て 仮想IPリソースで使用するNICと、DataKeeperのミラーリング等で使用するNICには、必ず別々のサブネットを用意して割り当てます。
- サブネットマスクは「/32」に設定 IPリソースを作成する際、クラウド特有のルーティング競合を避けるため、サブネットマスクは必ず
255.255.255.255 (/32)に設定します(これはクラウド環境共通の必須設定です)。 - ロードバランサーの活用 VIPを機能させるためのILBを適切に構成し、LifeKeeperの可用性をさらに高めるために「LB Health Check リソース」の導入も検討しましょう。
▼【図解】Azure環境におけるネットワーク構成のNG/OK例
3. 今回の「困った!」事例②:スプリットブレイン対策とQuorumの迷い
❓ 事象の概要(困った!)
「Azure環境でスプリットブレイン対策を行いたいのですが、StorageモードやMajorityモードなど選択肢が多く、どれを選べばいいか迷っています。Azureの共有ディスクは使えるのでしょうか? また、複数クラスタがある場合、Witnessサーバーはクラスタごとに必要ですか?」
🔍 原因究明のプロセスと判明した根本原因
スプリットブレイン(ネットワーク分断により両ノードがアクティブになってしまう現象)の対策はクラスター運用の要ですが、クラウドでは共有ストレージの扱いやネットワーク構成がオンプレミスと異なるため、構成の選択に迷うお客様が多数いらっしゃいます。 サポートからの回答により、Azure環境における最適なアプローチが整理されました。
💡 具体的な解決策(できた!)
お客様の要件や環境に合わせて、以下のいずれかの手法を選択するのがベストプラクティスです。
- パターンA:共有ディスクを利用する場合 v9.6.2以降(Linux版の場合)、Azure共有ディスクを用いた「SCSI-3 Persistent Reservations」によるI/Oフェンシングがサポートされています。共有ストレージを利用できる構成であれば、これが推奨の対策の1つとなります。
- パターンB:サーバー構成(Majorityモード)を採用する場合 クラスターノードとは別のサーバーを「Witness(監視)サーバー」として立てて多数決をとる手法です。Witnessサーバーは、クラスターノードと異なる可用性ゾーン(AZ)に配置することが推奨されます。
★嬉しいポイント:複数のLifeKeeperクラスターが存在する場合、1台のWitnessサーバーを複数クラスタで「共用(相乗り)」することが可能です。これにより、構築コストと運用負荷を大幅に削減できます!
▼【図解】複数クラスタでのWitnessサーバー共用(相乗り)イメージ
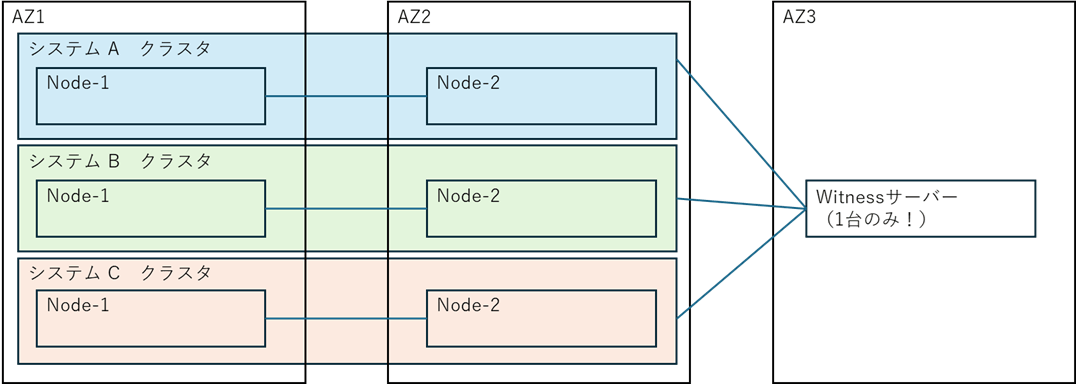
クラスタごとにWitnessサーバーを立てる必要なく、
1台のWitnessサーバーで複数のシステムを監視してコストが削減出来るわね!
4. 補足事例:DataKeeperのパフォーマンス設計(同期 vs 非同期)と潜むリスク
Azureのようなクラウド環境(あるいは遠隔地へのDR構成)でDataKeeperを利用する際、避けて通れないのが「同期モード」と「非同期モード」の選択です。 ここでは、設計時に必ず議論になる「リージョン間の距離(ネットワーク遅延)」と、「障害発生時のリスク」の2つの観点から解説します。
1. 物理的な距離(レイテンシ)が性能に与える影響
DataKeeperの同期モードは、稼働系で書き込みが発生するたびに、ターゲット側へデータを送り、その「書き込み完了通知(ACK)」が戻ってくるまでアプリケーションの処理を一時待機させます。
- 同一リージョン内(可用性ゾーン:AZ間など): 遅延が極めて小さいため、同期モードでも実用的なパフォーマンスが得られることが多いです。
- リージョン間(東日本-西日本間など): ネットワークの「物理的な距離」に応じて通信遅延(レイテンシ)が大きくなります。同期モードを選択した場合、この遅延がそのまま「アプリの書き込みレスポンス低下」として現れます。
- 設計のポイント: 東日本と西日本を跨ぐようなDR(災害対策)構成で同期モードを採用する場合は、「性能低下を許容してでもデータ保全を優先する」という明確な合意が必要です。パフォーマンスを最優先とするなら、距離の影響を受けにくい「非同期モード」が第一の選択肢となります。
2. 障害発生時のデータロスと自動フェイルオーバー
非同期モードを選択する際、もう一つ理解しておくべきなのが「障害時の挙動」と「計画的な切り替え時の挙動」の違いです。
- 同期モード: 常に両ノードのデータが一致しているため、障害時もデータロスが発生せず、最高レベルのデータ品質を保てます。
- 非同期モード: 稼働系の書き込みを優先し、同期はバックグラウンドで行います。
⚠️ 【重要】非同期モードの落とし穴: 稼働系が突然ダウンした場合、待機系への自動フェイルオーバー自体は正常に実行されますが、まだ転送されていなかった「未同期のデータ(キュー)」は、フェイルオーバー時にすべて破棄(データロス)されます。これにより、復旧後にデータ不整合が生じるリスクがある点に注意が必要です。
💡 【補足】計画的な切り替えは安全: メンテナンス等で「手動でのスイッチオーバー」を行う場合は、LifeKeeperが未同期のデータをすべて送り終えてから切り替える動作をします。そのため、非同期モードであっても手動切り替えであればデータロスや不整合は発生しません。
【結論:どう選ぶべきか?】
Azure環境における判断基準は以下のようになります。
| 項目 | 同期モード(推奨:同一リージョン/AZ間) | 非同期モード(推奨:リージョン間/DR構成) |
|---|---|---|
| 重視する点 | データ品質・完全一致(ロスなし) | アプリケーションの処理速度(レスポンス) |
| 距離の影響 | 距離(東日本-西日本など)があると遅延する | 距離に関わらず書き込み速度に影響しない |
| 障害時の自動切り換え (フェイルオーバー) |
ロスなし・不整合なし | 直前のデータ破棄・不整合のリスクあり |
| 計画時の手動切り替え (スイッチオーバー) |
ロスなし・不整合なし | ロスなし・不整合なし(同期完了を待つため) |
💡 さらに深掘り!:非同期モードで「データ不整合」はどこまで起きる?
「非同期モードでデータが破棄されると、ファイルが壊れてOSやDB(Oracle等)が起動しなくなるのでは?」と不安に思う方もいるかもしれません。しかし、DataKeeperにはそのリスクを最小限に抑える**「書き込み順序の整合性(Write Order Fidelity)」**という重要な仕組みがあります。
- 書き込み順序の保証: DataKeeperはブロック単位で同期を行いますが、ソース側で書き込まれた順序を厳密に守ってターゲット側へ転送します。そのため、「新しいブロックだけが先に届き、古いブロックが欠落する」といった不自然な状態は発生しません。
- 「停電直後」と同じ状態(クラッシュ一貫性): 障害発生時のターゲット側のディスクは、理論上**「ソース側のサーバーがある一瞬の時点で突然停電した際のディスク状態」**と等価です。
- 復旧のメカニズム: 最新の数ブロックが失われたとしても、ディスク全体としては「過去のある時点」の整合性が保たれています。そのため、フェイルオーバー後のOS(NTFS/ReFS等)やデータベース(Oracle等)は、自身の標準的なリカバリ機能(ログのロールバック等)を使って、不整合を解消し正常に起動することが可能な設計となっています。
【結論】
非同期モードは「直前のデータ(数秒分など)」を失う可能性はありますが、「システムが二度と立ち上がらなくなるようなファイル破損」を防ぐための高度な転送制御が行われています。パフォーマンスを優先しつつ、実用的な可用性を確保できるのが、DataKeeperが選ばれる理由の一つです。
5. 「再発させない!」ためのチェックリスト&ベストプラクティス
これまでの事例を踏まえ、Azure環境での構築前・設定時に確認していただきたいチェックリストを作成しました。ぜひ日々の運用や新規構築時にお役立てください!
✅ 再発防止策(Azure構築前・設定時のチェックリスト)
【ネットワーク・IP設計】
- 仮想IPリソースに割り当てるサブネットマスクは
255.255.255.255 (/32)に設定しているか? - 各サーバーのNIC(IPリソース用とミラーリング用など)には、それぞれ異なるサブネットを割り当てているか?(※同一サブネットは未サポート)
- 仮想IPを機能させるためのロードバランサー(ILB等)は適切に設計されているか?
- LB Health Checkリソースの導入を検討し、フェイルオーバーの確実性を高めているか?
【Quorum・データ保護設計】
- スプリットブレイン対策として、自社環境に合ったフェンシング手法(SCSI-3 PR、Majorityモード等)を正しく選定できているか?
- Majorityモードの場合、Witnessサーバーはクラスタノードと異なる可用性ゾーン(AZ)に配置するよう設計しているか?
- DataKeeperの同期モードは要件に合っているか?(LAN環境/データ品質重視=「同期」、WAN環境/レスポンス重視=「非同期」)
💡 ベストプラクティス
- Azure特有の設定マニュアルを必ず参照する Azure環境はオンプレミスや他のクラウドと動作原理が異なる部分があります。構築時は公式マニュアルの「Azure 特有の設定について」を必ずご一読いただき、OS(Windows/Linux)ごとの差異も確認してください。
- Witnessサーバーの効率的な活用 複数クラスタを運用する場合、MajorityモードのWitnessサーバーは1台で共用可能です。無駄なリソースを省き、コストの最適化を図りましょう。
- ログの監視ポイントを把握する フェイルオーバーの成否やスプリットブレイン対策の挙動は、Linuxであれば
/var/log/lifekeeper.logに記録されます。運用監視ツール等と連携し、このログを適切に監視する仕組みを整えることが安定稼働への近道です。
6. まとめ
いかがでしたでしょうか。Azure環境でLifeKeeperを安定稼働させるためには、クラウド特有のネットワーク仕様(ILB連携やサブネット要件)と、ストレージ仕様(スプリットブレイン対策)を正しく理解することが成功の鍵となります。 「オンプレと同じで大丈夫だろう」と思い込まず、事前に公式ドキュメントや本記事のチェックリストを活用して、落とし穴を回避してくださいね!日々の運用でここを意識すれば、不要なトラブルは確実に防げます。
7. 次回予告
次回の連載テーマは「カテゴリ4:DataKeeperの落とし穴:データ保護とパフォーマンスのバランス」です。 DataKeeperのミラー同期トラブルや、性能ボトルネックと障害時動作の確認ポイントについて、実際のサポート事例からディープに解説します。お楽しみに!
📚 本連載のバックナンバー
過去のトラブル事例と解決策もぜひあわせてご覧ください!
カテゴリ1:リソース起動・フェイルオーバー失敗の深層
▶【リソース起動・フェイルオーバー失敗の深層 #1】EC2リソースが起動しない!クラウド連携の盲点とデバッグ術 – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #2】ファイルシステムの思わぬ落とし穴:エラーコードから原因を読み解く – TechHarmony
▶【リソース起動・フェイルオーバー失敗の深層 #3】設定ミス・通信障害・バージョン違いの深層と再発防止策 – TechHarmony
カテゴリ2:OS・LKバージョンアップで泣かないために
▶【OS・LKバージョンアップで泣かないために #1】OSバージョンは変えていないのに!?カーネル更新の「落とし穴」と互換性の真実 – TechHarmony
▶【OS・LKバージョンアップで泣かないために #2】「設定が消えた!?」「亡霊IPが警告!?」を防ぐロードマップ:単純な上書き更新に潜む落とし穴と回避策 – TechHarmony
カテゴリ3:クラウド環境特有の落とし穴
▶【クラウド環境特有の落とし穴 #1】良かれと思った自動復旧が仇に!?AWS環境(EC2/Route53/S3)でハマる構成と回避策 – TechHarmony
▶【クラウド環境特有の落とし穴 #2】オンプレ感覚の「同一サブネット」はNG!?Azure環境のネットワーク要件とQuorum設計の最適解