
SCSKの畑です。
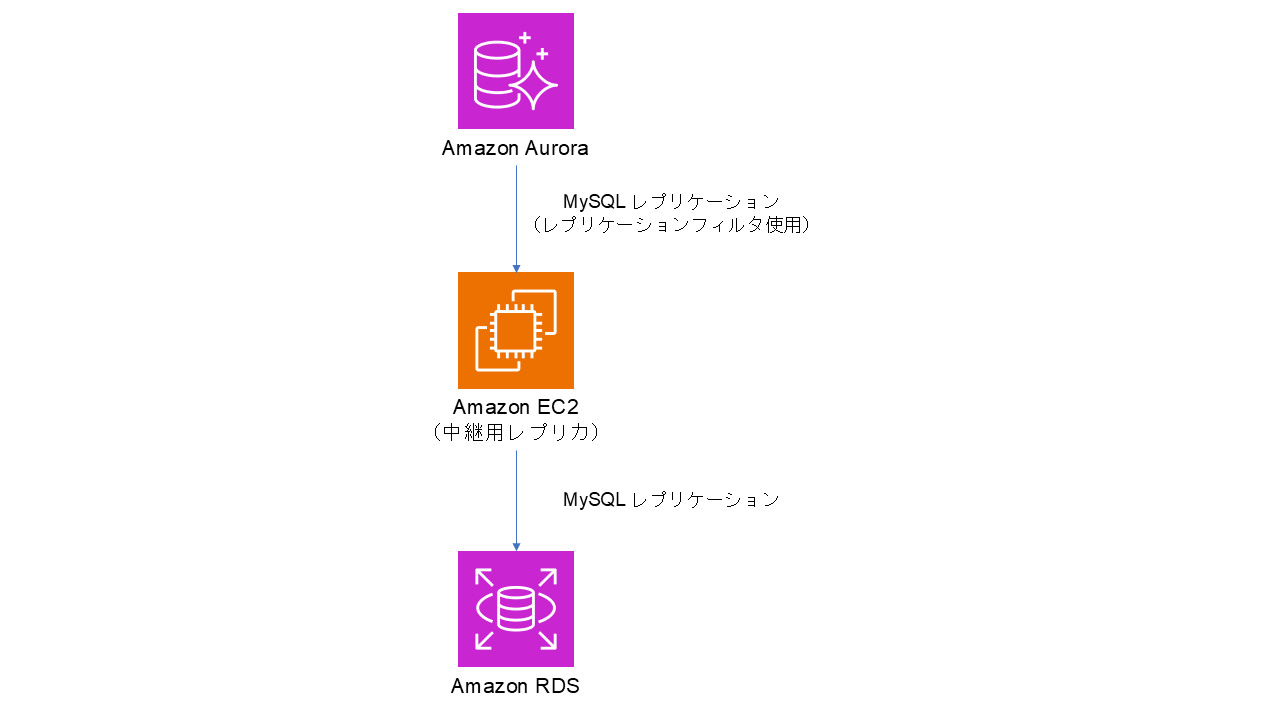
先般のエントリで予告していた通り、なぜ以下のような MySQL レプリケーション構成を取っているのかについて、幾つかの観点から説明していきたいと思います。
補足その1:レプリケーションフィルタ仕様の差異
まず真っ先に疑問として浮かぶであろう点は、何故 Aurora と RDS の間にわざわざ中継用レプリカとして EC2 上の MySQL を挟んでいるのかだと思います。以下のように直接 Aurora と RDS の間でレプリケーションを構成してしまえば 1 台インスタンスを減らせますし、レプリケーション構成としても AWS マネージドにできます。そして何より、先般のエントリで取り上げたような EC2 の AZ 障害を考慮する必要がなくなります。

正直メリットしかない、というか当初は私自身もこの構成にできないかを考えていたくらいなのですが、それができない理由が冒頭の構成図でも言及している「レプリケーションフィルタ」機能にあります。その名の通りレプリケーション対象のオブジェクトをフィルタリングするための機能で、以下の通りAWS のドキュメントに記載のある通り RDS や Aurora においても使用することができます。本構成ではテーブル単位のレプリケーションフィルタ(下記ドキュメントだと replicate-do-table に該当)を使用しています。

では何が問題なのかと言うと、MySQL オリジナルのバイナリと RDS/Aurora 間に、レプリケーションフィルタのパラメータの文字数制限(仕様)の差異があることです。具体的には以下の通り、RDS/Aurora には MySQL オリジナルのバイナリにはない制限があります。そして、現行環境におけるレプリケーションフィルタの文字数が 2000 文字を超えているため、上記構成を取ることはできませんでした。
- MySQL オリジナルのバイナリ:明確な制限なし(よって MySQL 側の内部仕様に準ずる)
- 現行環境では 2000 文字以上のフィルタ設定が動作している状況
- RDS/Aurora:2000文字
もちろん、以下のような構成上の代替案はいくつか考えられるのですが、いずれもそれぞれ不可能な理由が明確であったため、最終的には EC2 上で MySQL オリジナルのバイナリを中継用レプリカとして立てる構成に決定しました。
- RDS/Aurora の文字数制限に収まるようにフィルタリング要件を見直す
- 本案件における移行要件(非互換を極力排除して AWS に移行(リフト)すること)に適合しないため NG
- アプリケーション側の大幅な改修が必要でありそもそも現実的ではない
- 本案件における移行要件(非互換を極力排除して AWS に移行(リフト)すること)に適合しないため NG
- レプリケーションフィルタを使用せず、全てのテーブルをレプリケーションするように変更
- 本案件における移行要件(非互換を極力排除して AWS に移行(リフト)すること)に適合しないため NG
- 論理的には可能だがレプリケーション遅延など性能への影響が大きい上、バイナリログの転送量が増えることでレプリケーション先データベースのストレージ使用量も合わせて増えてしまう
- 本案件における移行要件(非互換を極力排除して AWS に移行(リフト)すること)に適合しないため NG
- データベース単位のレプリケーションフィルタ(replicate-do-db)とテーブル単位のレプリケーションフィルタを併用することで、後者の文字数を減らして制限に収まるようにする
- データベース単位のレプリケーションフィルタを使用できる対象がないため NG
- 正規表現が使用できるレプリケーションフィルタ(replicate-wild-do-table)を使用することで文字数制限に収まるようにする
- 実装自体は可能なものの、ルールがかなり複雑になってしまい運用上の支障が大きいため NG
- EC2 の代わりに RDS/Aurora を複数インスタンス立てた上で、それぞれのインスタンスごとにレプリケーションフィルタ設定を分割することで文字数を減らして制限に収まるようにする
- NG、理由は次項にて説明するので割愛
補足その2:大元のソースが同じ DB のマルチソースレプリケーション構成における弊害
さて、前項目でもったいぶって割愛した構成案ですが、図にすると以下の通りとなります。言葉で説明するとややこしいのですが、要はRDS/Aurora を複数台立ててレプリケーションフィルタ対象のテーブルをそれぞれ分割することで、RDS/Aurora のレプリケーションフィルタの文字数制限に収まるようにするのが狙いです。(図では RDS ですがこの構成であれば Aurora でもいけるはず)

現行のレプリケーションフィルタ設定を維持しつつ、中継用レプリカに RDS/Aurora を採用できる現実的な構成案としてはおそらく唯一です。RDS が 2 台構成となることに伴うコストの増大や、2 台が直列構成となる以上稼働率への影響は避けられませんが、EC2 の AZ 障害を考慮する必要がなくなるメリット自体も大きいと考え手元で検証していました。その結果、運用管理上問題になるであろう挙動が判明したためお蔵入りになってしまいました。
具体的には、上流の Aurora で一部の DDL(CREATE DATABASE 文など)を実行した際に、上記構成図の 中継用レプリカ_1 と 中継用レプリカ_2 両方から同一の DDL 文が下流の RDS に同期されてしまい、更新の競合が発生することで片側のレプリケーションが停止してしまうという挙動です。手元での検証結果となりますが、対象となる DDL 文は以下の通りです。
- CREATE/ALTER/DROP DATABASE 文
- CREATE/ALTER/DROP EVENT 文
- CREATE/ALTER/DROP FUNCTION 文
- CREATE/ALTER/DROP PROCEDURE 文
上記 4 つの内、CREATE DATABASE 文以外の 3 つについてはスキーマ(MySQL においてはデータベースと同義)にオブジェクトが紐つくため、上記構成図における レプリケーションフィルタ_1 と レプリケーションフィルタ_2 の対象スキーマが異なる場合、本事象は発生しません。しかし、残念ながら本構成においては単一スキーマにおけるレプリケーション対象のテーブルだけで文字数制限(2000 文字)を超過してしまうため対象となります。そして、CREATE DATABASE 文はサーバレベルのオペレーションとなるため問答無用で競合してしまいます。
補足その3:Aurora MySQL と RDS for MySQL のレプリケーション機能差異
ということで EC2 周りの構成についての言及は一段落なのですが、下流の RDS についても疑問を持たれるケースもあるかと思います。上流は Aurora にしているのになぜ?という疑問ですね。
この疑問に対する回答はシンプルで、Aurora はマルチソースレプリケーションをサポートしていないからです。具体的には以下のように、他のデータベースとのレプリケーションも構成しているため必然的に RDS を選択する必要があるということです。逆に言うと、もし Aurora がマルチソースレプリケーションをサポートしていた場合は、下流でもそのまま Aurora を使用していたと思います。

なお、AWS のドキュメントをざっと見る限りは明記されてはいないのですができるとも書いていない上、現時点では RDS でマルチソースレプリケーションを構成する際に使用するプロシージャが Aurora では提供されていないので確かだと思います。どっかに書いてあった気がするんですけども・・

まとめ
レプリケーションフィルタの仕様差異については最初知らなかったのですが、正直この差異によりある意味冗長な構成を組まないといけないというのはちょっとモヤモヤしてしまうところはあります。Aurora MySQL ならまだ分かるのですが、RDS for MySQL は Aurora との相対的なサービスの位置付けを考えると、MySQL オリジナルとより互換性のある仕様であって欲しかったところです。
当初は小ネタのつもりでしたが当時あれこれ検討していたためか筆が乗ってしまい思ったより長くなってしまいました。次回のデータベース関連のトピックこそ、ちゃんと小ネタになると思います。。
本記事がどなたかの役に立てば幸いです。