

 本記事は 夏休みクラウド自由研究 8/6付の記事です。 本記事は 夏休みクラウド自由研究 8/6付の記事です。 |
こんにちは。SCSKの山口です。
最近、Google CloudのData Fusionでパイプラインを構築する機会が多くあり、その中でも「Wrangler」のプライグインを多く使用したので、その際に便利だった機能をご紹介します。
※本ブログではData Fusionパイプラインの基本的な構築方法については言及していませんので、構築方法等については下記をご参照ください。
Cloud Data Fusion
概要
まずData Fusionについて簡単にご説明します。
Data Fusionは、データパイプラインを素早く構築、管理できる、クラウドネイティブのフルマネージドサービスです。
フルマネージドサービスなので、インフラの管理なしでパイプラインを構築することが可能です。
そして、何よりマウスだけで視覚的にパイプラインを構築することが可能なため、直感的な操作で、コードを意識することなくETLパイプラインをデプロイすることができる点が長所です。
利用できるプライグイン
プラグインとは、Data Fusionの機能を拡張するために使用できるカスタマイズ可能なモジュールのことです。
下記の種別のプラグインが用意されています。
- ソース
- 変換
- 集計
- シンク
- エラーコレクタ
- アラートパブリッシャー
- アクション
かなり数があり、一つひとつ説明すると膨大な文量になるので詳細は下記ドキュメントをご覧ください。
実践:WrangerプラグインでGCSのファイルを加工してBigQueryテーブルに取り込む
実現したいこと
今回実現したいことは以下の内容です。
- 下記「member」テーブルに、氏名と電話番号(ハイフンなし)のデータをロードします。
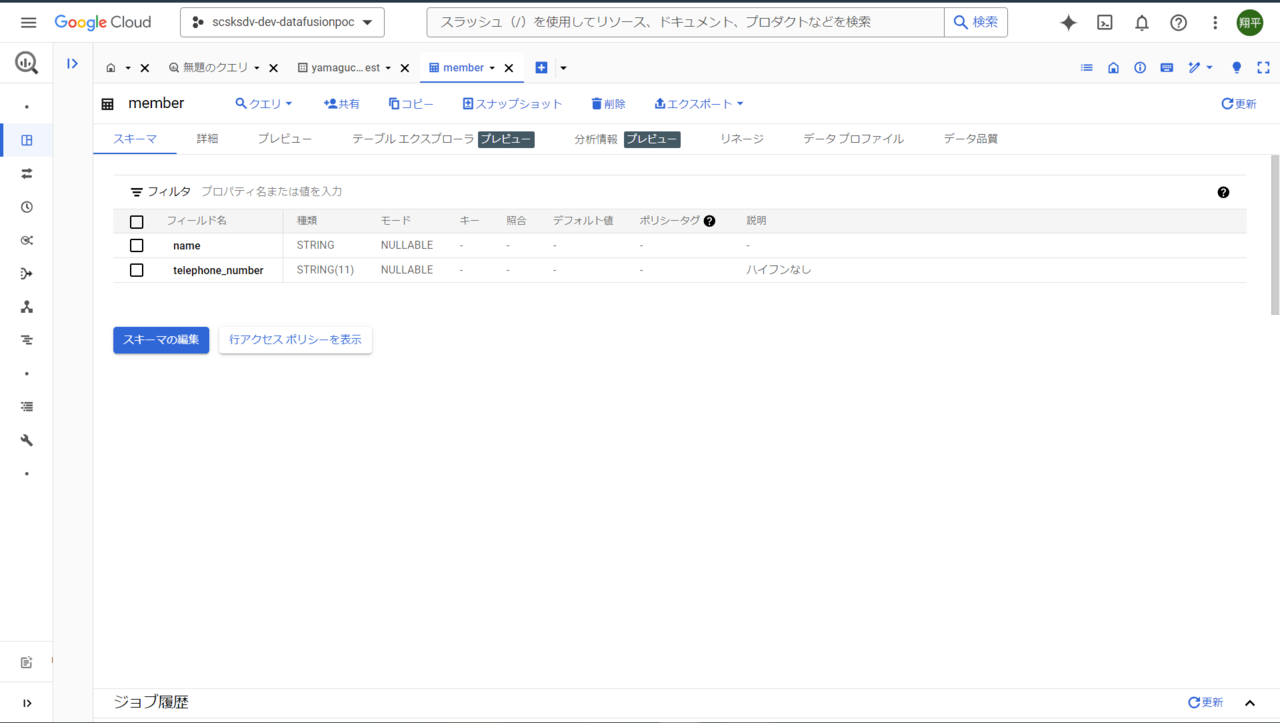
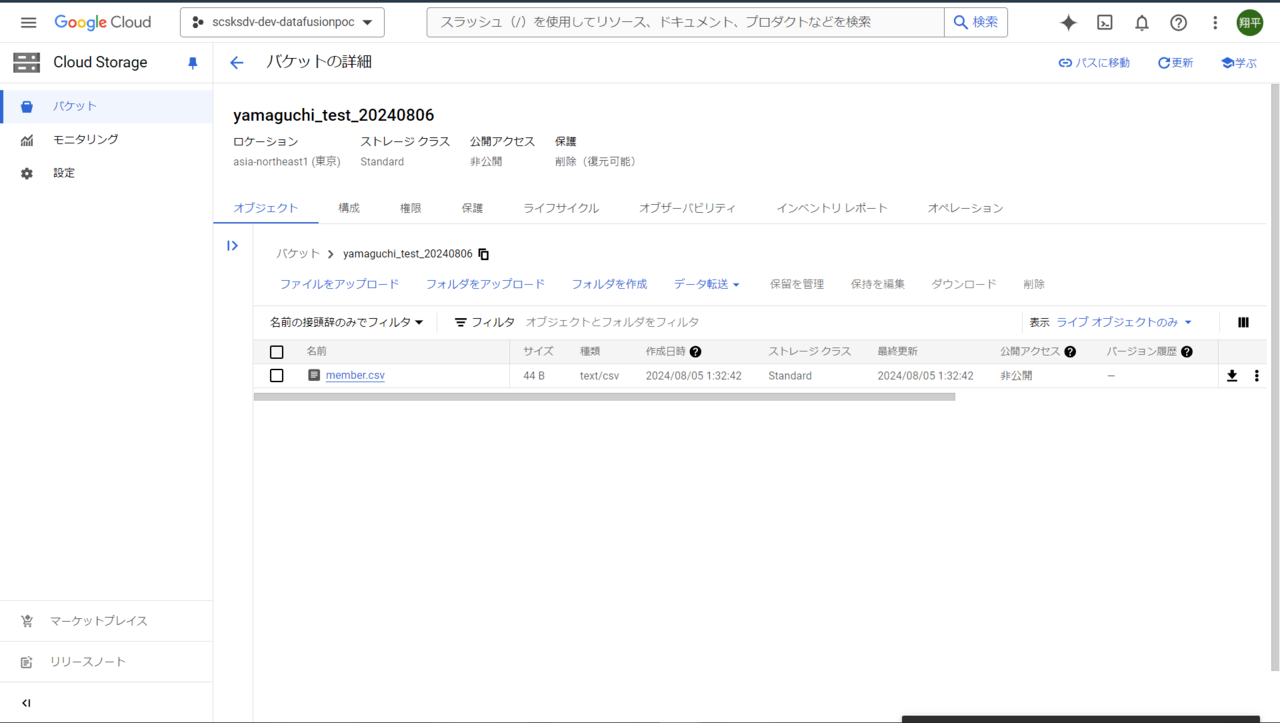
- データのインポート元はGCSファイルに置いているCSVファイルです。
- 「member」テーブルの電話番号カラムにはハイフンなしの番号(最大長:11)をロードしたいですが、GCS内のCSVファイルにはハイフンが含まれています。
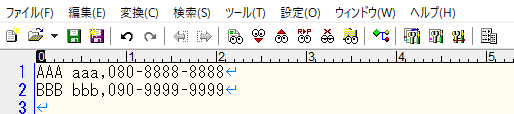
- GCSからCSVファイルをBigQueryテーブルにインポートする際に、「電話番号」カラムのハイフンを取り除きたいです。
- これを、Data Fusion(Wrangerプラグイン)で実現します。
パイプライン構築
では早速パイプラインを構築していきます。
Source
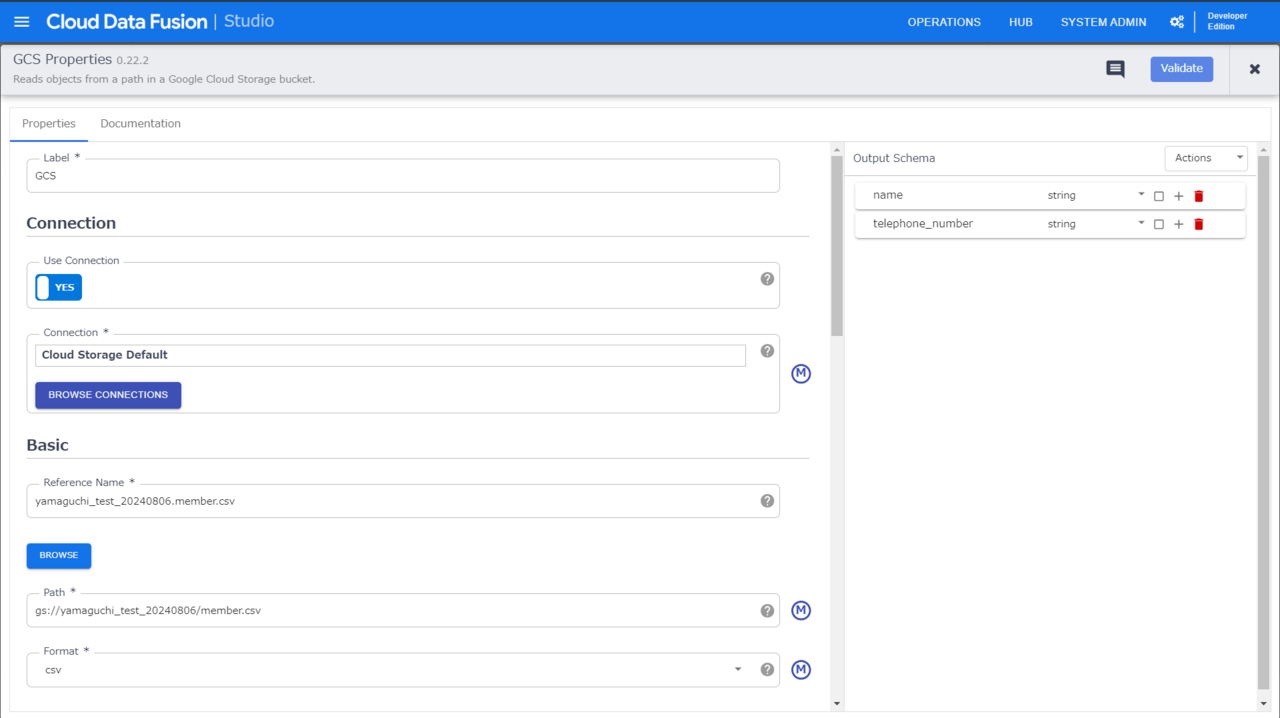
今回はデータソースとして「GCS」プラグインを選択します。
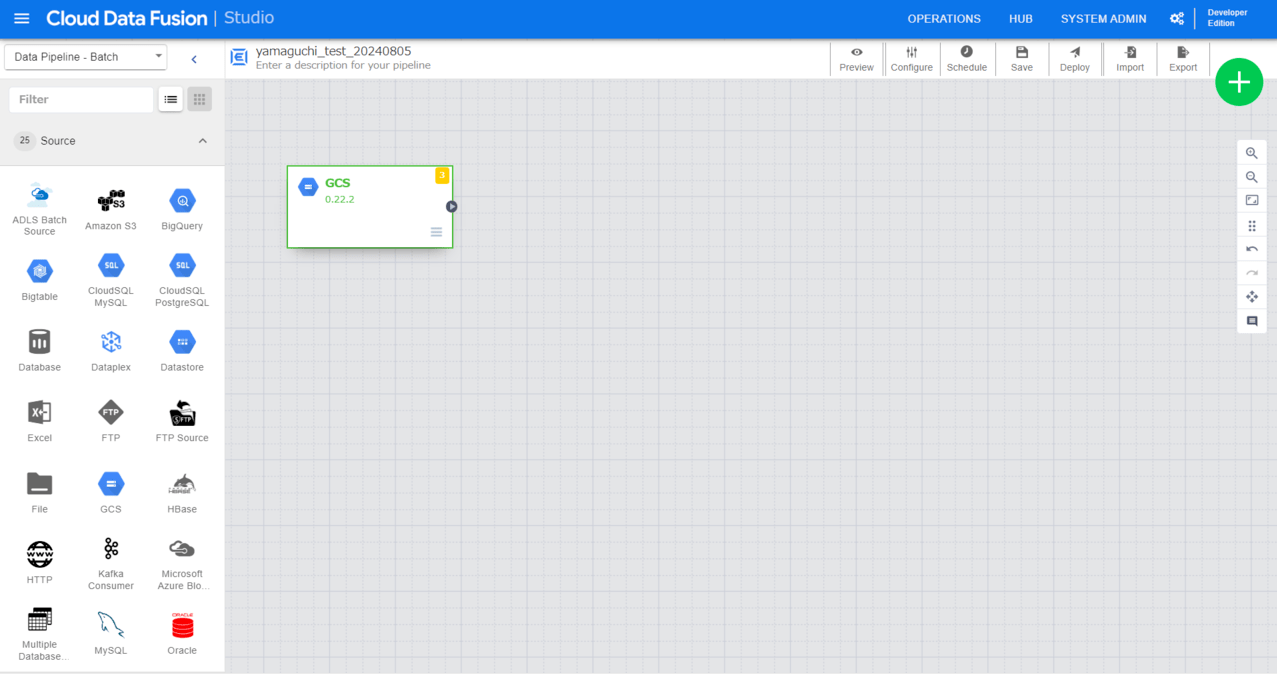
左ペインから「GCS」を選択し、パイプライン構築画面に表示されたGCSアイコンから「Properties」を設定します。
今回は、インポート対象のCSVファイルを「BROWSE」より検索し、選択します。
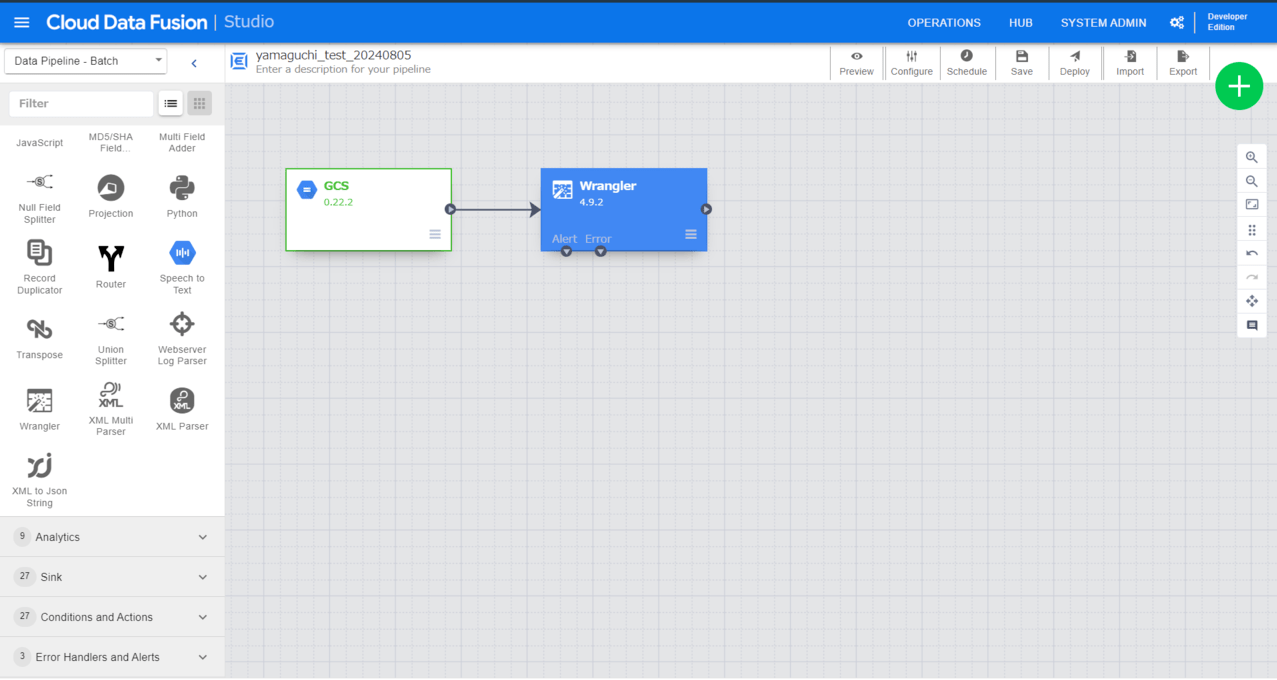
Transform
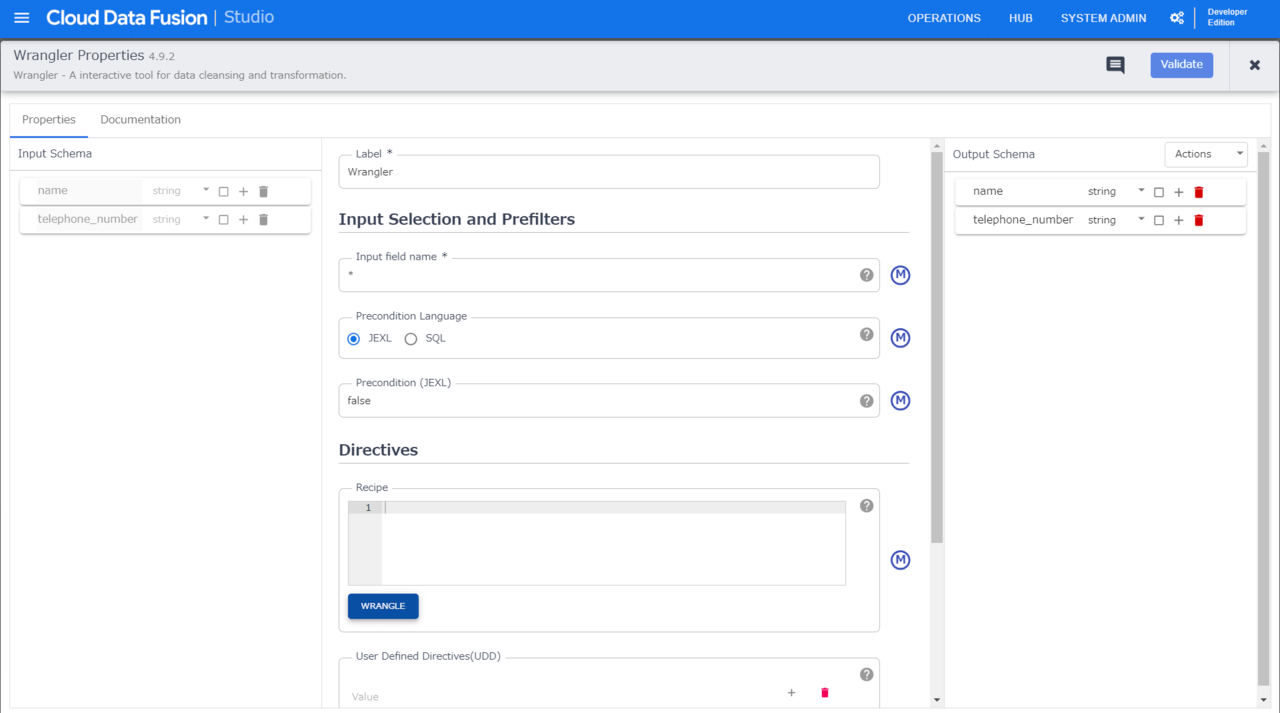
今回は変換のプラグインとして「Wrangler」プラグインを使用します。(本ブログのメイン)
propertyを開き「Directives」の「WRANGLE」ボタンを押下します。
今回のソースファイルを選択します。
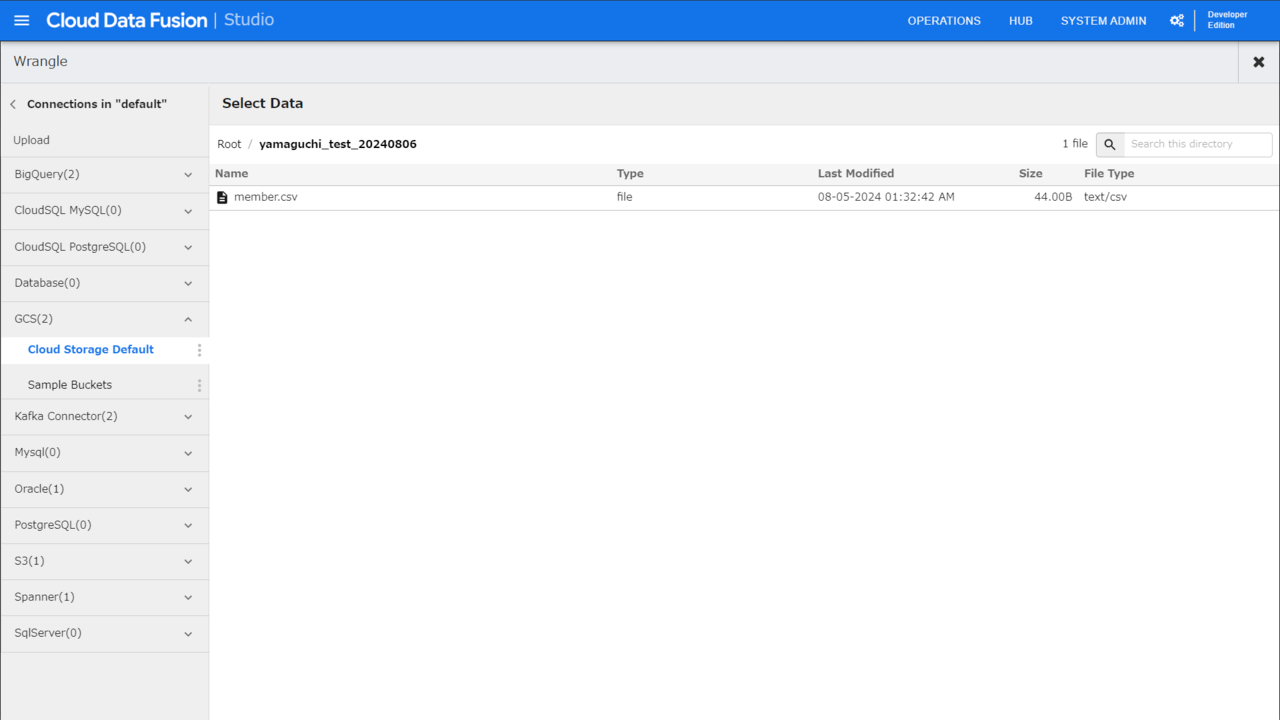
インポートしたいファイルが表示されたら準備OKです。
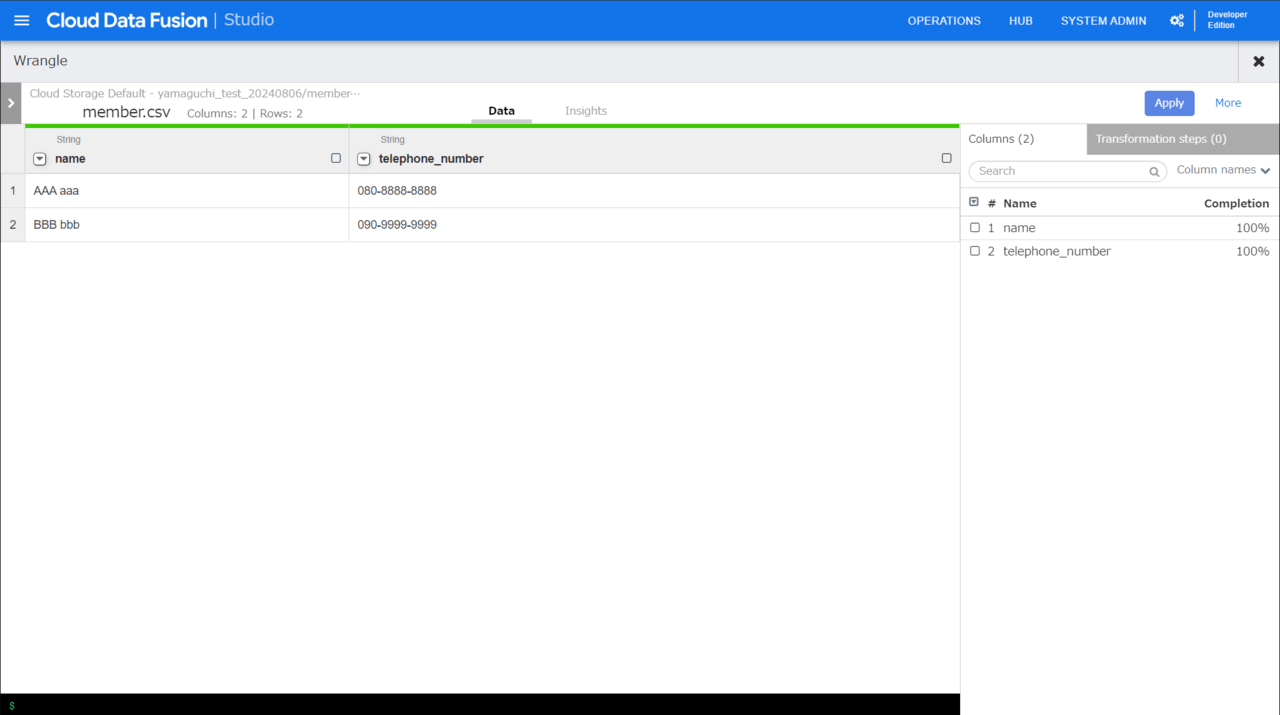
さて、今回やりたいことをおさらいします。
やりたいことは、「telephone_number」カラム内のハイフンを取り除くことです。
この作業を実際にWRANGLE画面でやってみます。
対象カラム「telephone_number」の横のプルダウンを開き。「Find and replace」を選択します。
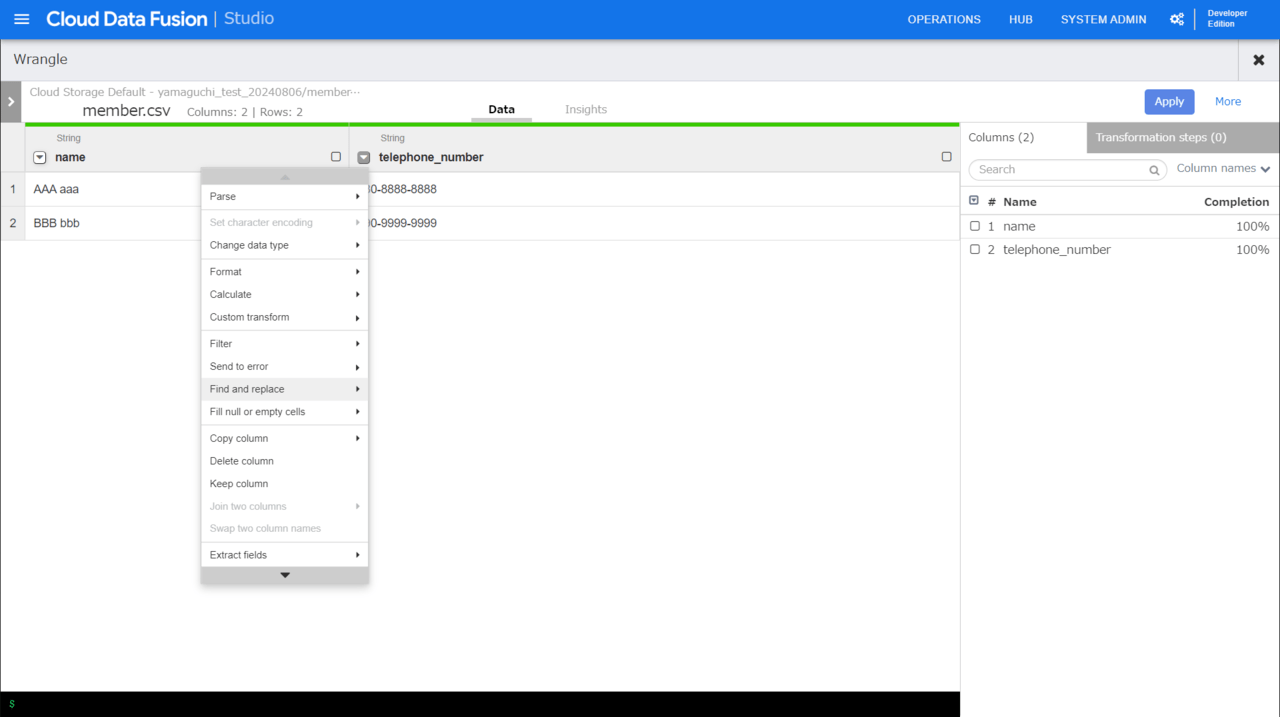
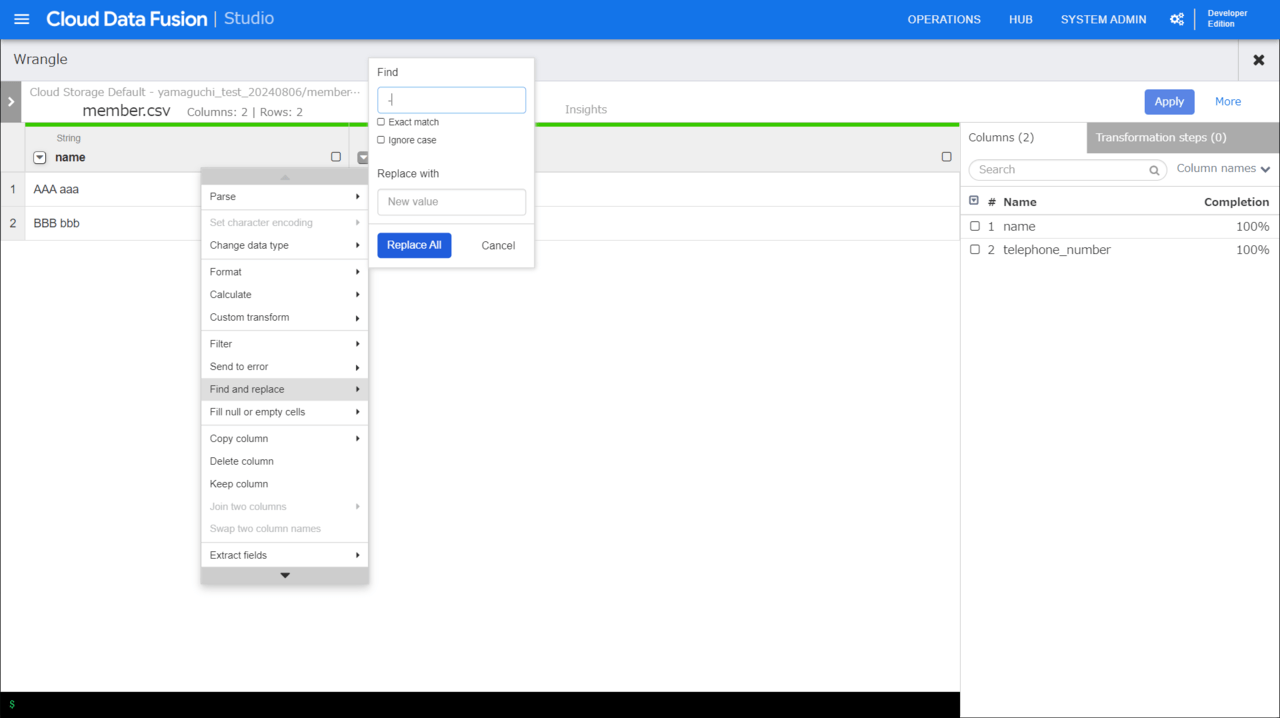
下記を入力します。
- Find:-(ハイフン)
- Replace with:(何も入力しない)
Replace Allを押下すると、ハイフンが削除されていることがわかります。
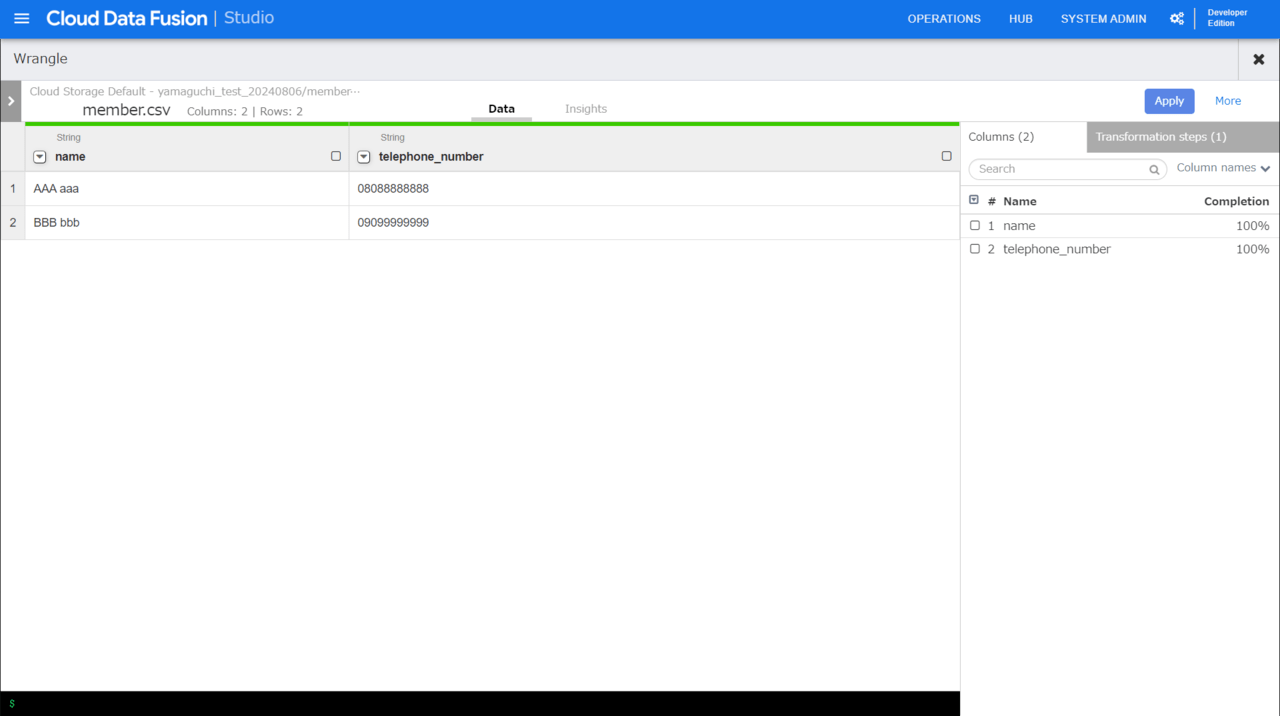
ここまでは何の驚きもないかもしれませんが、画面右ペインの「Transformation steps」をクリックすると、先ほどやった作業のレシピを記述してくれています。
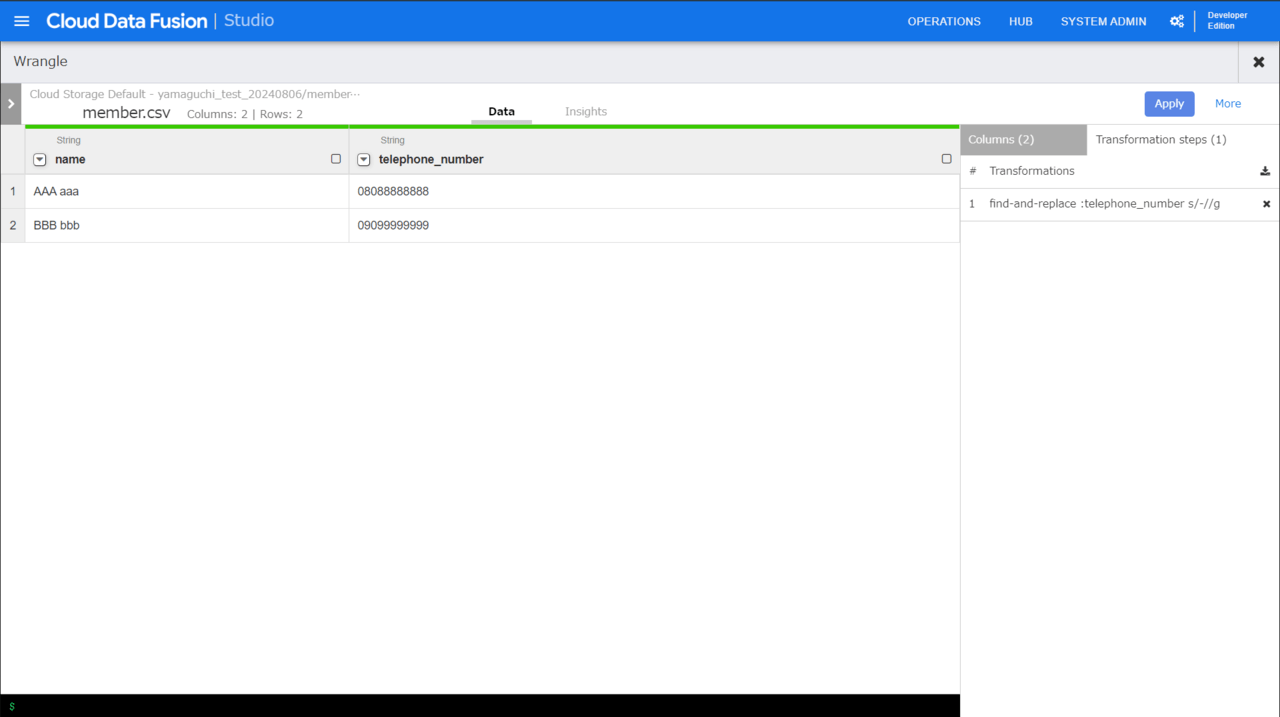
さらに、右上の「Apply」ボタンを押下すると、
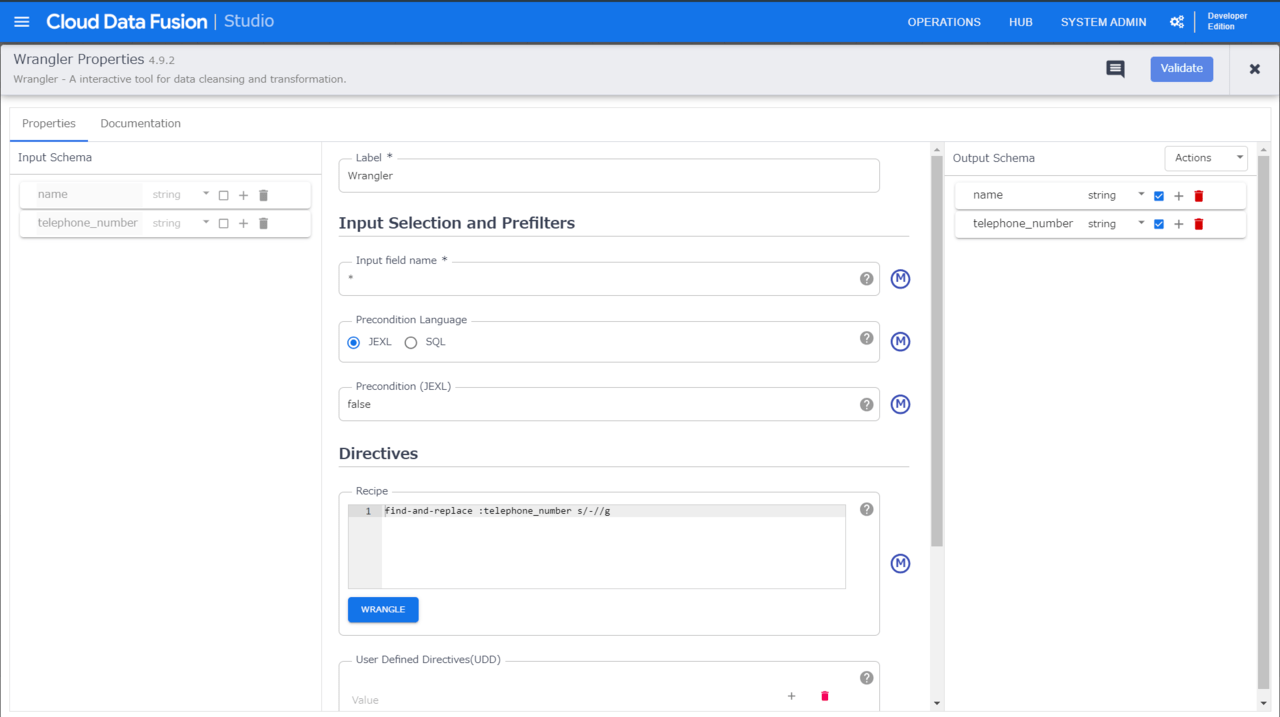
「Directives」の「Recipe」に先ほどの内容を記述してくれています。
つまり、実際のデータを見ながら手で作業した内容を自動的にレシピに反映してくれている。というわけです。
レシピに直接コードを入力することなく、やりたい変換処理を実際に行うだけで自動的に記述してくれる大変便利な機能です。
Sink
さあ仕上げです。データの最終的な出力先(sink)に「BigQuery」プラグインを選択し、宛先テーブルを指定します。
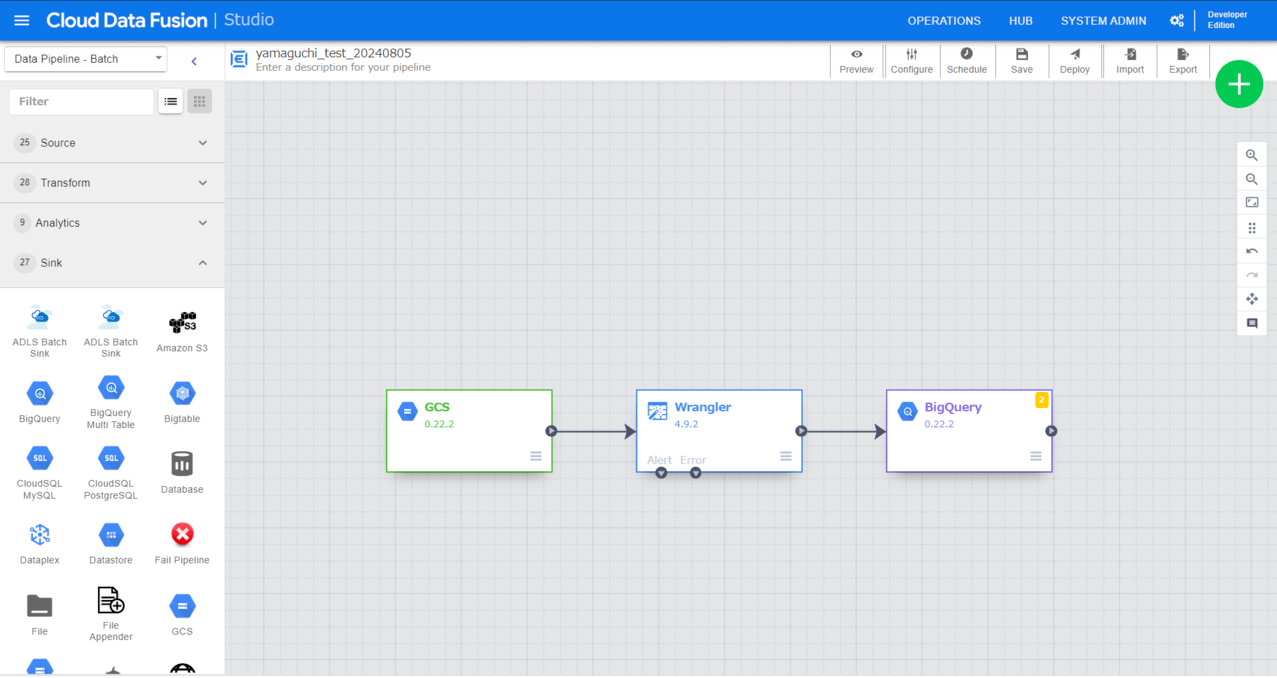
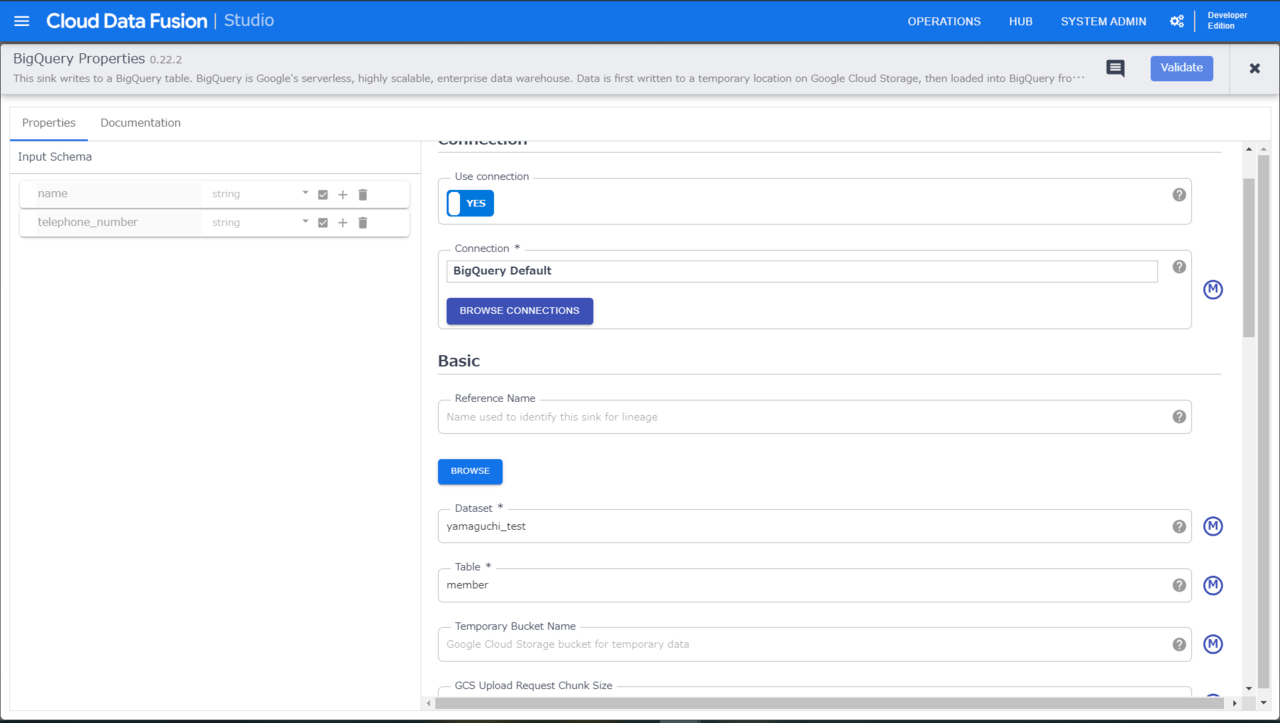
以上でパイプライン構築は完了です。
豆知識
プラグインをつなげていくと、矢印がジグザグになったりと画面が煩雑になることがあります。
このような場合は、プラグインを全選択し、画面右ペインの「Align」をクリックすると、プラグインを綺麗に整列してくれます。
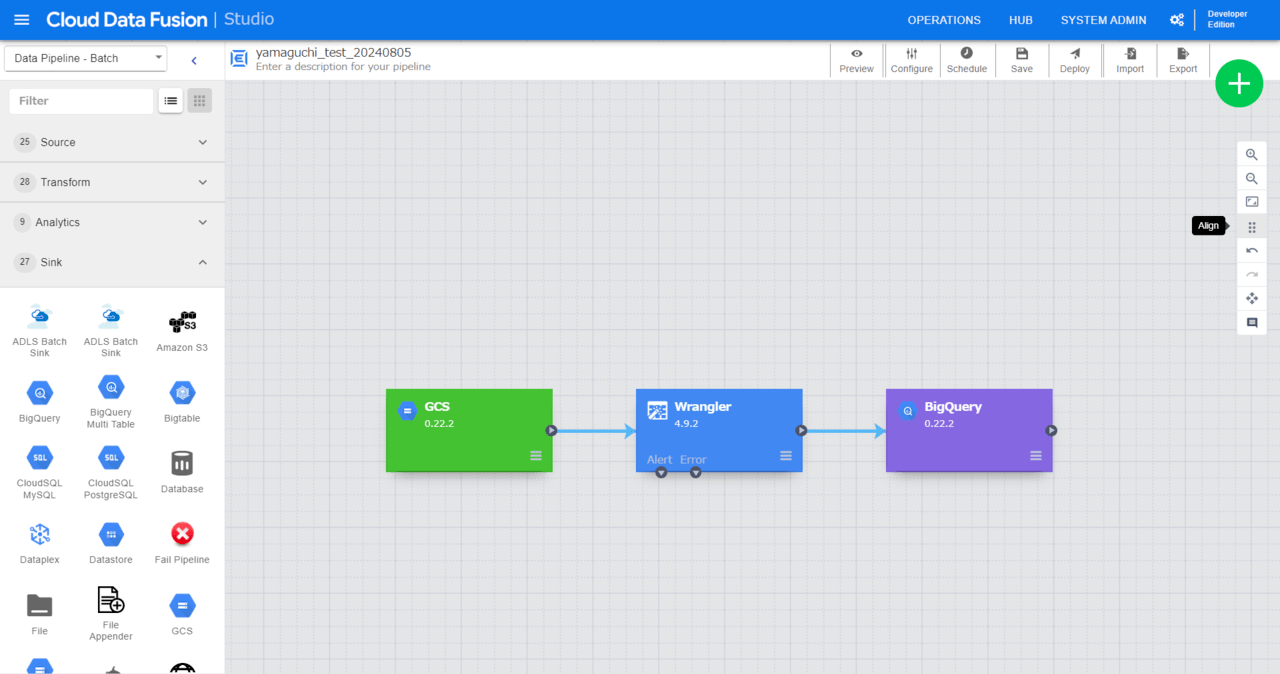
以上、A型の筆者からの豆知識でした。
パイプライン デプロイ・起動
パイプラインをデプロイし、起動(Run)します。
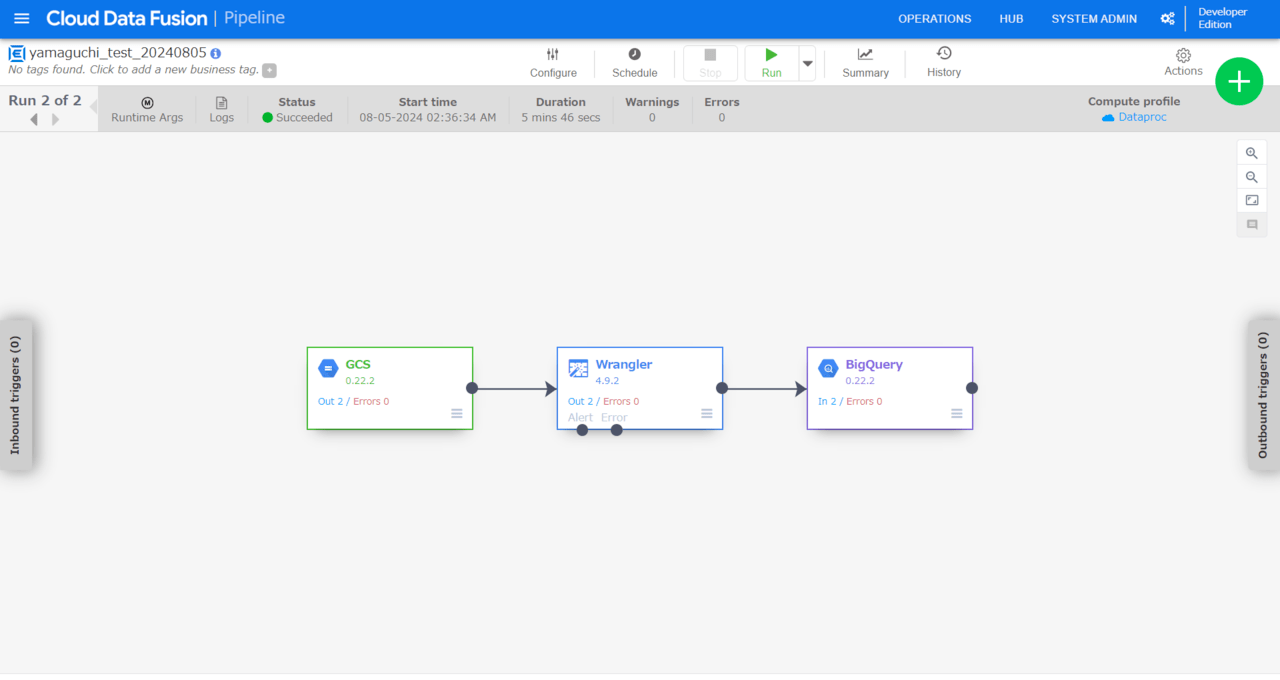
パイプラインは無事成功しました。最後に出力先のテーブルを確認します。

電話番号のカラムにハイフンなしのデータが取り込まれています。大成功です。
まとめ
今回はData FusionでWranglerプラグインを活用してパイプラインを構築しました。
最初にも述べた通り、Data Fusionを使用するメリットの一つは、視覚的・直感的な操作でパイプラインが構築できる点です。
今回紹介したWranglerプラグインの使い方は、そのメリットを最大限活用したものだと思います。
また、Wranglerプラグインでは正規表現を使用した変換等も可能なので、柔軟なデータ加工が可能です。
皆さんも是非ご活用ください。