

ブログリレー前回の記事では、バックエンドのあれこれを齋藤さんが記事にしてくれましたが、本日はフロントエンド編ということで、AWSパラメータシート自動生成ツールのGUIをどのような技術を使用して実現したかをご紹介できればと思います!
フロントエンド概要
フロントエンドは下記のような流れでバックエンド(パラメーターシート出力)に処理が引き継がれます。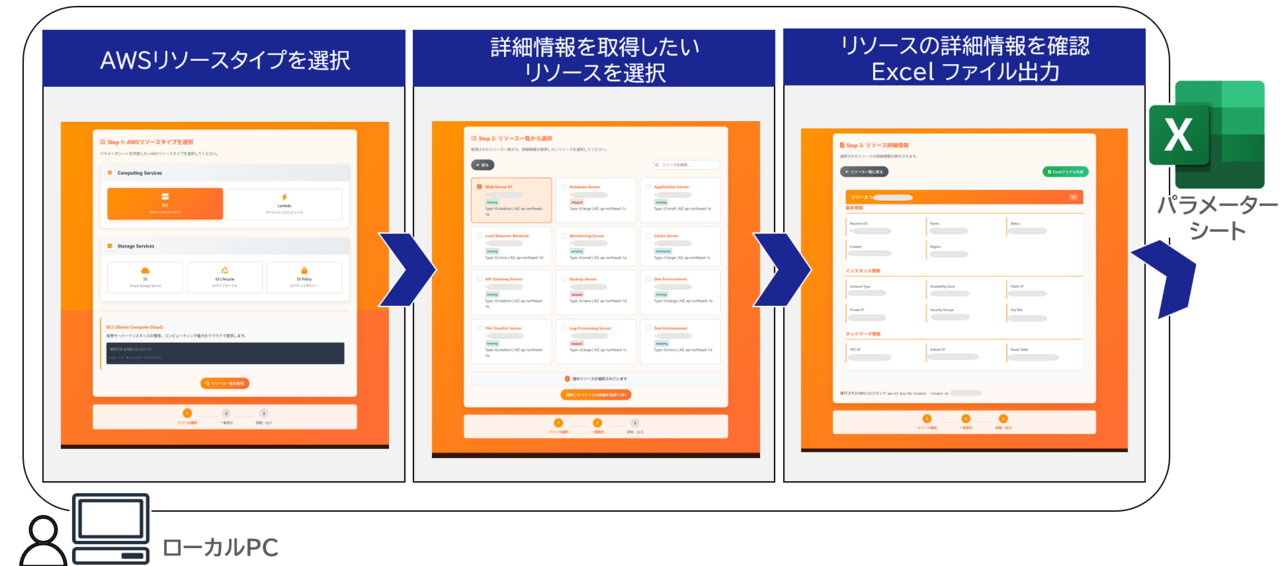
上記処理のうち、本記事のフロントエンドは「GUI」と「GUIを提供するサーバー」部分を担当しています。
使用した技術
フロントエンド実現のために使用した主な技術とその役割は下記の通りです。
| 技術 | 役割 |
| JavaScript | クライアント側、サーバーサイド側のロジックを記述するために使用した言語 |
| Node.js | JavaScriptの実行環境であり、アプリケーション全体の実行基盤 |
| Express.js | WebサーバーおよびREST APIなどのサーバーサイド側の機能を提供してくれるWebフレームワーク |
| HTML5 + CSS3 | 画面構造とデザイン |
フロントエンドは、クライアント側、サーバーサイド側も一貫してJavaScriptを使用して実装しています。
サーバーサイド側の開発として、Ruby + Rails や Python + Django といった組み合わせもある中で、JavaScript + Node.js を使用した理由としては、以下の通りです。
- 案件で JavaScript を触る機会があり慣れている
- よく耳にする組み合わせでなんかかっこいい
しかし、よくよく調べるとよく耳にする理由がありました。それについては以降で説明していきたいと思います。
Node.js
Node.jsとは?
そもそもNode.jsとは何者かというと、JavaScriptをサーバー上で実行するための開発環境です。
元々、JavaScriptという言語は他の言語と異なり、ブラウザ上で動作する言語であり、ローカル(OS上)環境では動作させることができない言語でした。
よって、ブラウザ上でしか動作しない JavaScript ではローカル環境にあるファイルを読みにいくことができないという問題がありました。
その制限を取っ払ってくれたのが、Node.jsという訳です。
Node.jsの特徴
Node.jsの特徴としては、主に以下の3つが挙げられます。
前のタスクが完了していない状態でも次のタスクを開始でき、非同期での処理を実現している。
そのため、大量のアクセスがあっても対応が可能である。
プログラムを実行する際に、1つずつ処理を行う。
一般的にシングルスレッドだと大量のアクセスがあった場合に制御することが難しくなるが、ノンブロッキングI/O処理によって、多くのアクセスがあってもリアルタイムでレスポンスが可能になる。
サーバーサイドアプリケーション、デスクトップアプリケーション、コマンドラインツールなどの幅広い用途で使用されるため、非常に多くのライブラリがある。
npmというパッケージ管理ツールを使用することにより、膨大なライブラリを簡単にインストール・管理することができる。
Express.js
ここまでで、Node.jsを使用した理由や用途は理解できたかと思いますが、あくまでもNode.jsはサーバーサイド側でJavaScriptを実行できるようにした実行環境であり、ただの基盤です。
フロントエンドを作成する上では、基盤の上に実際の機能を作成してあげる必要があります。
その実際の機能は一から作る必要はなく、既に用意されたひな形から作成することができます。
それにあたるのが、Express.jsです。
Express.jsとは?
Express.jsとは、Node.jsのための軽量で柔軟なWebアプリケーションフレームワークです。
フレームワークとはひな形とも言い換えることができ、様々なひな形が用意されています。
例えば、機能開発が簡単に実装できる以下のようなひな形が用意されています。
例えば、ユーザが / にアクセスしたら、トップページを表示する、/download/file.xlsx にアクセスしたら、ファイルをダウンロードするなどがある。
フロントエンド(ブラウザ)からのリクエストを受け取り、Web上でデータをやりとりするための操作を定義することができる。その操作には以下のものがあり、これらを定義することができる。
| HTTPメソッド | 操作 |
| GET | リソースを取得する |
| POST | リソースを作成する |
| PUT | 指定したIDのリソースを更新する |
| DELETE | 指定したIDのリソースを削除する |
また、HTTPヘッダーによるキャッシュ制御も可能で、同じファイルへの再リクエスト時のレスポンス時間を短縮できる。
どこに使用したの?
では、フロントエンド実現にあたってどこに活用したのかというと下記の通りです。
| 機能 | 使用箇所 |
| ルーティング機能 |
|
| REST API機能 |
|
| 静的ファイルの配信 |
|
苦労した点
リソースごとに異なるJSONファイル
フロントエンドでは、AWSのリソースの詳細情報を表示するために、AWS CLIコマンドを実行し、リソースの一覧を取得してきています。その一覧情報の構造が、リソースによって異なり、リソースごとに取得する情報を定義してあげることが苦労しました。
例:
EC2インスタンスの場合:
S3バケットの場合:
このように、同じ「リソース一覧を取得する」という処理でも、項目名やJSONファイルのネスト構造の深さが異なります。そのため、すべてのリソースに対して、どのキーからデータを取り出すか、IDとして何を使うかを個別に定義する必要がありました。
一方で、共通化できる部分は共通化し、できるだけ同様のコードで詳細情報を取得できるようにしてあげました。やはりコードの最適化には、AIを使用してあげるのが効率よかったです。
特殊なリソースの取得フロー
一般的なリソースの場合、取得フローは下記のようになります。
サービス選択 ⇒ リソース一覧から出力したいリソースを選択 ⇒ プレビュー画面表示 ⇒ Excel 出力
しかし、サービスの中には一発で一覧を取得できないサービスがあります。
例えば、ELBのターゲットグループの場合、ELBに紐づくターゲットグループを取得する必要があるため、まず最初にELBの一覧を取得し、その後にターゲットグループを取得する必要があります。よって、一覧の取得フローとしては下記のようになります。
サービス選択(ELBターゲットグループ)⇒ リソース一覧から出力したいリソースを選択(ELB)⇒ リソース一覧から出力したいリソースを選択(ターゲットグループ)⇒ プレビュー画面表示 ⇒ Excel 出力
このようにサービスによっては、中間ステップが存在するものもあるため、コードを共通化することができず、苦労しました。
まとめ
本記事では、AWSパラメータシート自動生成ツールのGUIであるフロントエンドで使用した技術について簡単に紹介しました。
実は、この取り組みはフロントエンドのアプリケーションを作成するつもりはなく、バックエンドのJSONファイルをパラメータシートに変換するアプリケーションのみを構築予定でした。しかし、使用するユーザー目線で考えると、やはりGUIがほしいということになり、開発に取り組みました。
普段はインフラ構築を担当する部署のため、初めて触れる技術が多く、開発には3~4か月ほどかかってしまいましたが、この取り組みを経てアプリケーションの知識をつけることができ、フルスタックエンジニアへと一歩近づいた気がします。
皆さんもぜひ、息抜きもかねて普段とは異なる分野の技術に触れてみるのはいかがでしょうか?
というわけで、私の投稿は以上です!
次回は、AWSパラメータシート自動生成ツールを使ってみたということで、藪内さんにバトンタッチしますので、ぜひそちらも閲覧いただければと思います。