

こんにちは、SCSKの松岡です🚩
SCSKが提供しているクラウドデータ活用サービスでは、データドリブン経営実現のためのステップを、「活用基盤」「可視化・分析」「連携・蓄積」「マネジメント」「高度活用」の5つに定義しています。
各ステップを実現するためのポイントと、さらにそれらを支えるモダンデータスタックの設計についてご紹介します!
データドリブン経営のための5つのステップ
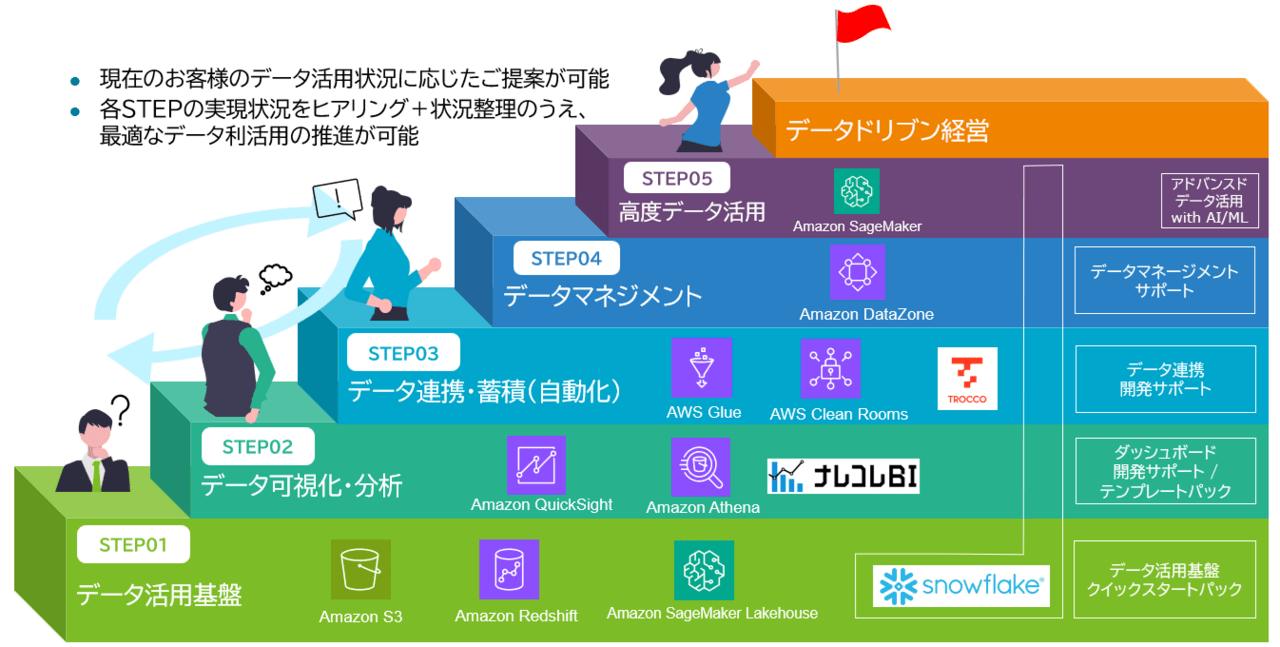
STEP01 データ活用基盤
データドリブン経営を実現するためには、まずデータを蓄積・活用するための基盤が必要です。
特に近年では、AI活用の文脈においてもデータ基盤の重要性が増しています。企業独自のデータをどのように収集・蓄積し、どのように活用していくかという観点において、データ活用基盤はすべての出発点となります。
前提として整理しておきたいのが、「データレイク」と「データマート」の役割分担です。 生のデータをそのままの形で保管する「データレイク」と、特定の分析目的に合わせて加工・最適化された「データマート」を適切に切り分けることで、データの鮮度と分析のスピードを両立させることができます。
初期段階で時間をかけすぎると、データ活用の本来の目的である「価値創出」までたどり着けないケースが多く見られます。そのため、テンプレートや既存の構成を活用し、スモールスタートで基盤を構築することが有効です。
また、基盤構築においてはコストと運用負荷も重要な観点です。
コスト最適化に優れており、運用負荷も少ないことから、管理の負担を抑えたい方に特に利用を推奨しています。
さらに、近年はデータレイク自体の進化も進んでいます。
従来のファイルベースのデータレイクではなく、Icebergのようなテーブルフォーマットを採用することで、検索性能や運用性を大きく向上させることが可能です。
STEP02 データ可視化・分析
基盤が整った後、次に重要になるのがデータの可視化・分析です。
ここでよくある課題が、「何を見ればよいか分からない」という点です。
単にBIツールを導入するだけでは、データ活用は進みません。業務でどのような意思決定をしたいのか、そのためにどのデータが必要なのかを明確にする必要があります。
また、導入初期段階ではテンプレートの活用が非常に有効です。あらかじめ分析の「型」を用意することで、ユーザーが迷わずデータ活用を開始でき、早期に成功体験を積めるようになります。
さらに近年では、BIのあり方自体も変化しています。
Snowflake IntelligenceのようなエンタープライズAIエージェントの登場により、ユーザーは複雑な操作をせずとも、自然言語でデータに問いかけ、必要なインサイトを得ることが可能になりつつあります。

STEP03 データ連携
データ活用を拡張していく上で不可欠なのがデータ連携です。企業内には複数のシステムが存在し、それぞれにデータが分散しています。これらを統合し、分析可能な形に整える必要があります。
データドリブン経営を推進する上でも、社内の多種多様なデータ源とスムーズに連携できているかどうかが、意思決定の判断材料を増やすことにつながります。
また、AI活用を見据えた場合、社内の多様なデータ源と連携できているかどうかが、AIが回答できる領域の広さや精度に直結します。

また、AI活用を見据えた場合、画像や音声、PDFといった「非構造化データ」の重要性も増しています。
STEP04 データマネジメント
データ活用が進むにつれて、データの管理(ガバナンス)が極めて重要になります。「データの所在が分からない」「権限管理が煩雑」といった課題は、活用が活発な現場ほど顕在化しやすいためです。
複数のソースシステムからデータが集約される中で、各データの定義や意味を管理する「データカタログ」の重要性は、組織の成熟とともに増していきます。
また、AWS環境においては、マルチアカウント構成での運用が一般的です。そのため、アカウントを跨いだデータ共有や統制も避けては通れないポイントとなります。
全社的なデータ活用の文脈においては、アカウント横断でデータカタログを一元管理できるか、そして組織間でのデータ共有をいかにセキュアかつ容易に行えるかが、データ活用をさらに加速させるための重要な要素になります。
SageMaker Catalogであれば、中央のデータ基盤管理者に過度な負担をかけることなく、各部署間で直接「利用申請・承認」のワークフローを回すことが可能です。部署ごとの判断で迅速にデータを共有できる仕組みを整えることで、ガバナンスを効かせながらも、データの直接的な広まりを加速させることができます。
STEP05 高度データ活用
STEP 04までの「基盤・可視化・連携・管理」が整うことで、いよいよデータ活用の真髄である高度な分析・予測のフェーズへと進むことができます。
STEP 01〜04を確実に踏むことで、AIやMLのポテンシャルを100%引き出せる組織へと進化できます!

データ活用基盤の核となるモダンデータスタック
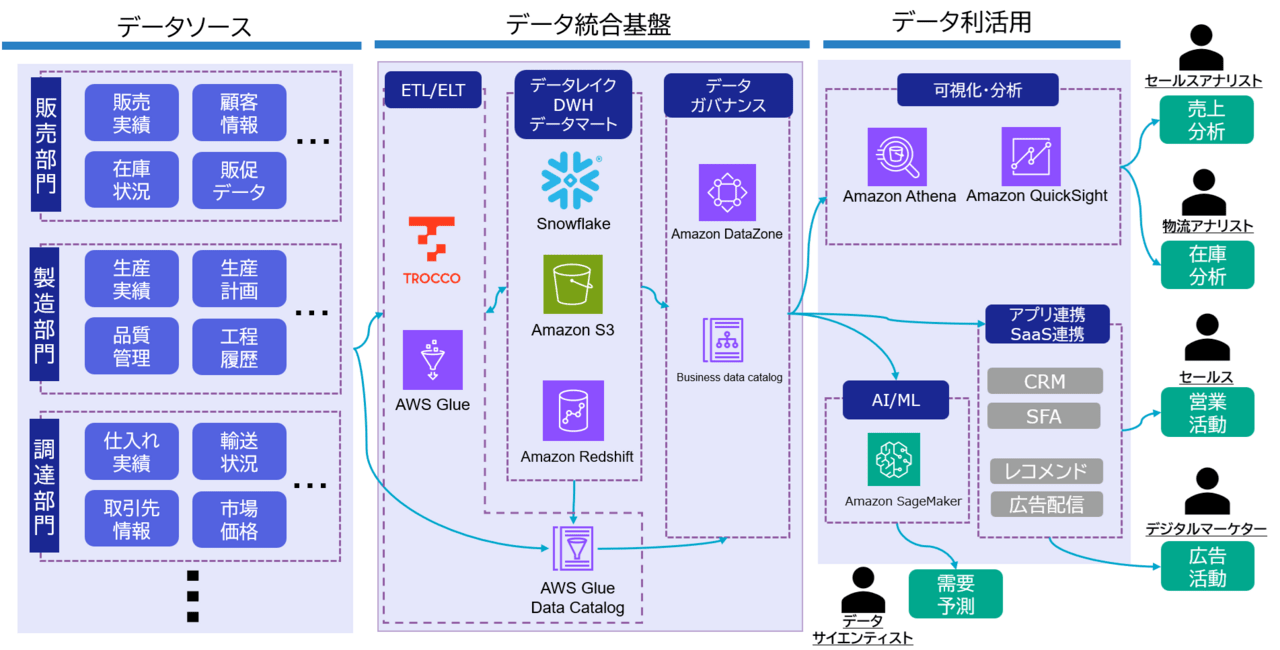
各STEPを乗り越え、データ活用基盤が完成した場合の例はこのようになります。
データ活用基盤を構成するサービスは、近年めまぐるしく進化しています。
先ほど記載したように、データレイクにおいては従来のS3に加え、S3 Tablesのようなパフォーマンスに特化した新しいサービスが登場しています。また、データ連携においても、ノーコードのETLツールからコードベースの統合サービスまで選択肢は増え続けており、組織のスキルセットに応じた柔軟な選択が可能になっています。
このように、状況の変化に合わせてサービスを変更したり、場合によっては使い分けたりすることを想定しておく方が良いです。
そこで重要になるのが、モダンデータスタックの考え方です。
モダンデータスタックとは、単一の製品やサービスに依存するのではなく、各領域でベストなクラウドサービスやSaaSを組み合わせて、柔軟なデータ活用基盤を構成する設計思想です。
例えば、
- データ蓄積:S3 / Snowflake
- データ連携:Glue / TROCCO
- 可視化:Quick / 各種BIツール
- データ管理:DataZone
といったように、それぞれの役割に応じて最適なサービスを選択し、疎結合に組み合わせていきます。
この考え方は、AI活用を前提としたAI-Readyなデータ基盤においても非常に重要です。
AIは単体で価値を生むものではなく、その根拠となるデータの品質や量、そしてアクセスのしやすさに大きく依存します。AI活用を成功させるためには、前段となるデータ基盤・データ連携・データマネジメントといった各STEPが適切に設計されていることが不可欠です。
まとめ
本記事では、データドリブン経営を実現するための5つのステップと、それを支えるモダンデータスタックの設計思想について紹介しました。
データ活用基盤は最初から巨大なシステムを目指すのではなく、段階的に、かつ柔軟なアーキテクチャで構築することがポイントであると考えています。
変化の激しいAI時代にも迅速に対応できる、データ基盤の実現をこれからも目指していきたいです!