
はじめまして。SCSKのすぐろです。
プレビュー版として実装されていたAWS DevOps Agentが2026年3月にGA(一般提供)されましたね。
インシデント発生時に自動で原因調査を行ってくれるサービスですが、実際にどこまで調べてくれるのかが気になったので、Amazon EC2上のWebサーバーで障害を発生させ、DevOps Agentの調査精度と限界を検証してみました。
AWS DevOps Agentとは
インシデント発生時に、複数のデータソースを横断的に分析し、根本原因の特定と緩和策の提案を自動で行うマネージドサービスです。AWSネイティブなCloudWatchメトリクス・CloudWatch Logs・CloudTrailに加え、Datadog、Dynatrace、New Relic、Splunk等のサードパーティ製監視ツールや、GitHub、GitLab等のCI/CDパイプライン、ServiceNow、PagerDuty等のチケットシステムとも連携できます。GA版ではAzureやGrafanaのサポートも追加されました。
料金
従量課金制で、エージェントがタスクに費やした時間に対して秒単位で課金されます。アイドル状態や待機中は課金されません。
| 課金対象 | 単価 |
|---|---|
| Investigations(インシデント対応) | $0.0083 / agent-second |
| Evaluations(インシデント予防) | $0.0083 / agent-second |
| On-demand SRE tasks(チャット) | $0.0083 / agent-second |
新規利用者には2ヶ月間の無料トライアルがあり、各月Investigation 20時間・Evaluation 15時間・チャット 20時間まで無料で利用できます。
検証のきっかけ
本番稼働中のWebサーバー(EC2インスタンス)のインシデント調査に使用するにあたり、以下の4点がきになりました。
EC2インスタンスへの影響はあるか
DevOps AgentのIAMマネージドポリシー(AIDevOpsAgentAccessPolicy)を確認すると、EC2に対しては ec2:Describe* 等の読み取り系APIのみが許可されています。セキュリティドキュメントにも「エージェントが利用可能なツールは、チケットやサポートケースのオープンを除き、リソースを変更することができない」と記載されています。つまり、DevOps Agentの導入・調査によってEC2インスタンスが変更・停止されることはありません。
参照: DevOps Agent IAM permissions
参照: AWS DevOps Agent Security
サーバーの中まで見に行ってくれるのか
DevOps AgentはAWSのAPIを通じて情報を収集します。OS内部に直接アクセスする機能はドキュメントに記載されていません。OS内部の情報を調査対象にするには、CloudWatch Agent等でCloudWatch Logsやカスタムメトリクスとして事前に送信しておく必要があります。
参照: About AWS DevOps Agent
参照: What is a DevOps Agent Topology?
どうやって調査しているのか
IAMポリシーにはSSMでコマンドを実行する ssm:SendCommand やSSH接続用の ec2-instance-connect:* は含まれていません。SSHやSSMでEC2に接続するのではなく、AWSのAPIを通じた読み取り専用アクセスのみで調査を行います。
サーバー内に何かインストールされるのか
EC2インスタンス内部にエージェントソフトウェアがインストールされることはありません。導入時に作成されるのはAgent Space(論理コンテナ)やサービスリンクロール等、AWSコントロールプレーン側のリソースのみです。
検証
検証環境
- EC2: t3.micro(Amazon Linux 2023)、httpd(Apache)をUserDataで起動
- CloudWatch Agent: 以下の設定でログ・メトリクスを送信
CloudWatch Agentの設定ファイル(/opt/aws/amazon-cloudwatch-agent/etc/config.json):
{
"metrics": {
"namespace": "DevOpsAgentTest",
"metrics_collected": {
"mem": {
"measurement": ["mem_used_percent"],
"metrics_collection_interval": 60
},
"disk": {
"measurement": ["used_percent"],
"metrics_collection_interval": 60,
"resources": ["*"]
}
}
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/messages",
"log_group_name": "/devops-agent-test/messages"
},
{
"file_path": "/var/log/httpd/error_log",
"log_group_name": "/devops-agent-test/httpd-error"
},
{
"file_path": "/var/log/httpd/access_log",
"log_group_name": "/devops-agent-test/httpd-access"
}
]
}
}
}
}
/var/log/messages をCloudWatch Logsに送信することで、OOM KillerなどカーネルレベルのイベントがDevOps Agentの調査対象になります。メモリ・ディスク使用率のカスタムメトリクスも送信し、標準メトリクス(CPU、ネットワーク等)と合わせてDevOps Agentが参照できるようにしています。
検証1: CPU高負荷
SSMで接続し、yes > /dev/null コマンドでCPUを100%に張り付かせた状態でDevOps Agentに調査を依頼しました。
調査依頼プロンプト:
EC2インスタンス(i-xxxxx )のCPU使用率が急上昇しました。原因を調査してください。
結果:
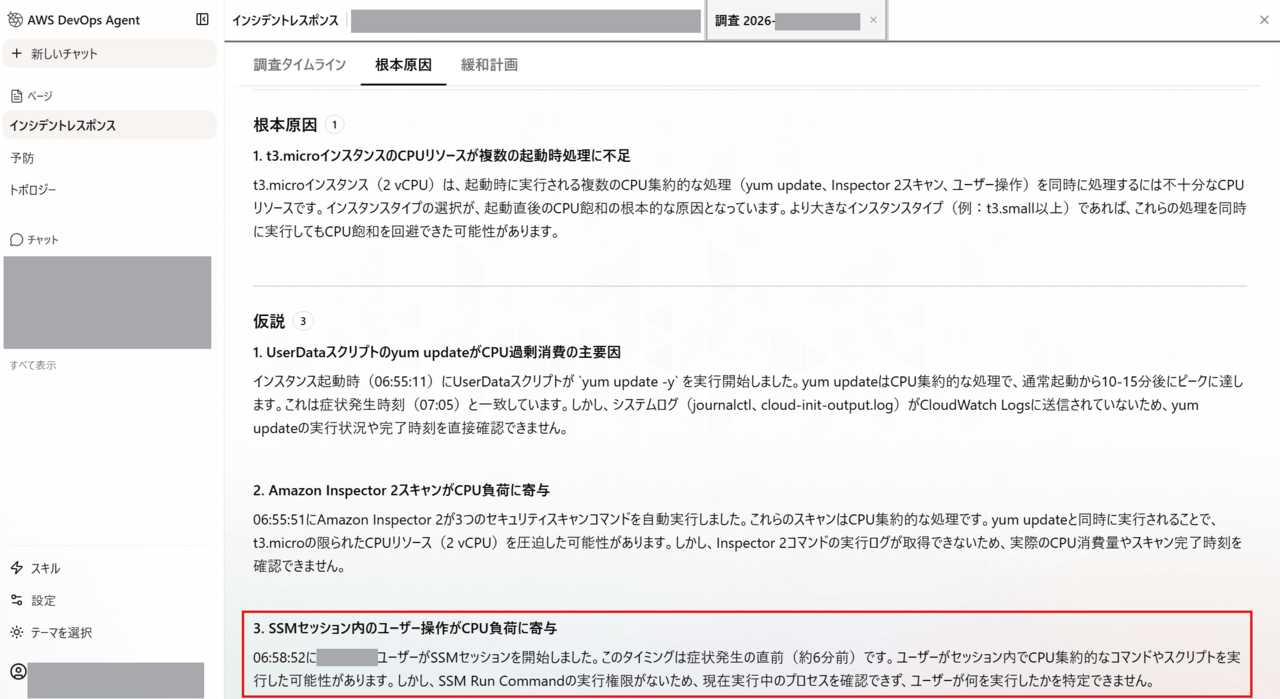
- CPU使用率が100%に達していることを正しく検知
- CloudTrailからタイムラインを構築し、同時刻のイベント(yum update、Inspector 2スキャン、SSMセッション開始)を列挙
- 「SSMセッション内でCPU集約的なコマンドを実行した可能性がある」と推測 → 実際に正しい方向の推測
- 調査した結果原因を断定できなかったので仮説を立てている
- 各仮説に「可能性がある」という表現を使い、断定を避けていた
- 「調査ギャップ」として確認できなかった事項を明確に報告
真の原因(yesコマンド)にはOS内部のプロセス情報がないため到達できませんでしたが、仮説と事実を区別した誠実な調査結果でした。
調査コスト: 約6分(360秒)→ $2.99($1=¥150換算で約¥448)
追加検証: SSMセッションログを有効にして再検証
検証1ではDevOps Agentが実行コマンドを特定できなかった原因は、SSMセッション内で何を実行したかのログがCloudWatch Logsに送信されていなかったためです。そこで、SSM Session ManagerのCloudWatch Loggingを有効にし、セッション中のコマンド入出力をCloudWatch Logsに記録する設定を追加した上で、同じCPU高負荷を再現して調査を依頼しました。
調査依頼プロンプト:
EC2インスタンス(i-xxxxx )のCPU使用率が急上昇しました。原因を調査してください。
結果:
- 根本原因を「IAMユーザーxxxxxによる意図的なCPUストレステストの実行」と正確に特定
- 実行コマンド(
for i in $(seq 1 $(nproc)); do (yes > /dev/null) & done)を特定 - 実行ユーザー、セッションID、起動されたプロセスのPIDまで特定
- 「計画的な負荷テストであり、システム異常やマルウェアではない」と正しく判断
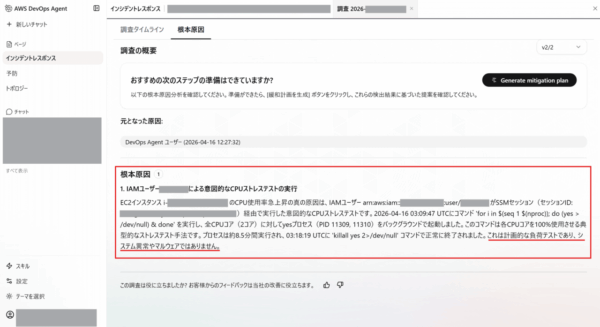
SSMセッションログという1つのデータソースを追加しただけで、検証1の「仮説止まり」が「正確な原因特定」に変わりました。DevOps Agentの調査精度がデータソースの充実度に直結することを改めて裏付ける結果となりました。
検証2: メモリ逼迫によるOOM Killer発動
stress-ng でメモリを枯渇させ、OOM Killerによってhttpdが強制終了される状況を作り、DevOps Agentに調査を依頼しました。検証1と異なり、OOM Killerのログが /var/log/messages → CloudWatch Logs経由でDevOps Agentの調査対象になります。
調査依頼プロンプト:
EC2インスタンス(i-xxxxx )上のWebサーバー(httpd、ポート80)が応答しなくなりました。原因を調査してください。
結果:
- 根本原因を「stress-ngツールによる意図的なメモリ枯渇テスト」と正確に特定
- 実行ユーザー(SSMセッションユーザー)を特定
- 実行コマンドとパラメータ(
stress-ng --vm 1 --vm-bytes 900M)まで特定 - OOM Killerが全httpdプロセス(PID含む)を強制終了したことをログから読み取り
- タイムラインを正確に構築(00:07:17 → 00:11:29 → 00:17:32)
- メモリ枯渇 → OOM Killer → httpd停止 という因果関係に正しく到達
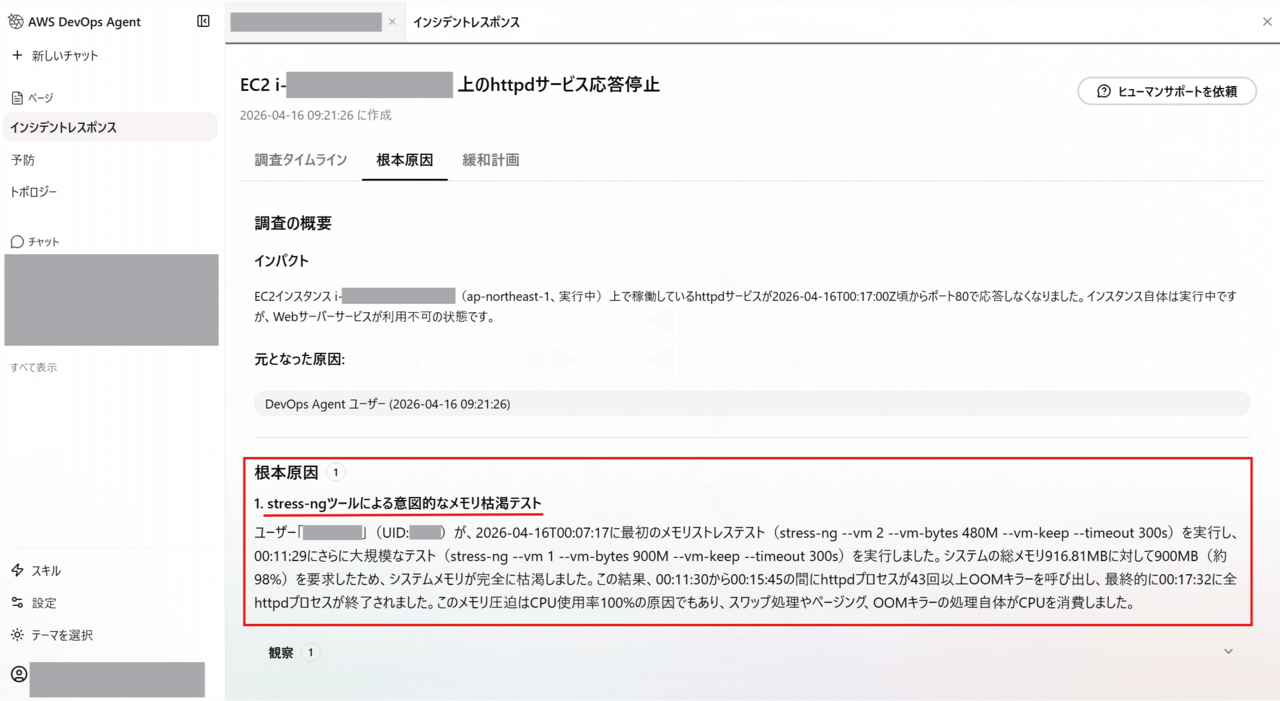
検証1では仮説止まりだったのに対し、CloudWatch Logsにカーネルログという明確な根拠があったことで、正確な原因特定ができました。
また、調査完了後に「緩和計画」という機能を実行したところ、stress-ngプロセスの停止 → httpdサービスの再起動 → 事後検証(HTTP 200 OK確認)まで、具体的なコマンド付きの復旧手順を提示してくれました。手順通りに実行してWebサーバーの復旧を確認できました。
調査コスト: 約5分(304秒)→ $2.52($1=¥150換算で約¥379)
わかったこと
良かった点
- AWSのAPI経由で取得できる情報を横断的に分析し、タイムラインを構築する能力は高い
- CloudWatch Logsに根拠となるログが存在する場合、実行コマンド・ユーザー・タイムラインまで正確に特定できる(検証2で確認)
- 調査ギャップ(確認できなかったこと)を報告する仕組みがある
- EC2インスタンスへの変更やエージェントのインストールは不要
- 従量課金制で、調査しなければ費用は発生しない
注意が必要な点
- OS内部のプロセス状態やローカルログには直接アクセスできない
- CloudWatch Logsに送信されていない情報は調査対象外
- データソースに根拠がない場合、仮説止まりになる(検証1で確認)
調査精度の比較
| 検証 | データソースの根拠 | 原因特定 | 評価 |
|---|---|---|---|
| 検証1(CPU高負荷) | △ メトリクスのみ | × 仮説止まり | 真の原因に到達できず |
| 検証1 追加検証(SSMセッションログ有効) | ○ メトリクス + SSMセッションログ | ○ 正確に特定 | コマンド・ユーザー・PIDまで特定 |
| 検証2(メモリ逼迫) | ○ メトリクス + OOM Killerログ | ○ 正確に特定 | コマンド・ユーザーまで特定 |
まとめ
DevOps Agentの調査精度は、データソースに残る根拠の有無に大きく依存します。検証1ではメトリクスだけでは仮説止まりでしたが、SSMセッションログを1つ追加しただけで正確な原因特定に変わりました。
導入を検討する場合は、DevOps AgentがAPIレベルで情報を取得できる環境を整備しておくことが重要だと感じました。CloudWatch Agentによるログ・メトリクスの送信はもちろん、CloudTrailの有効化やVPCフローログの設定など、DevOps Agentが参照できるデータソースを充実させて調査精度を向上させることで、インシデント調査はエージェントにお任せし、業務効率を向上させていきましょう!