

SCSKの畑です。
以前のエントリの続き・・ではないのですが、データメンテナンス機能に関する言及という観点は同じなのでその2としました。今回は、データメンテナンス機能の対象となる Redshift の特性を踏まえた上で、アプリケーションの実装において考慮する必要があったポイント及び機能について記載します。Redshift そのものというよりは、DWH の特性とある程度言い換えて良いかもしれません。
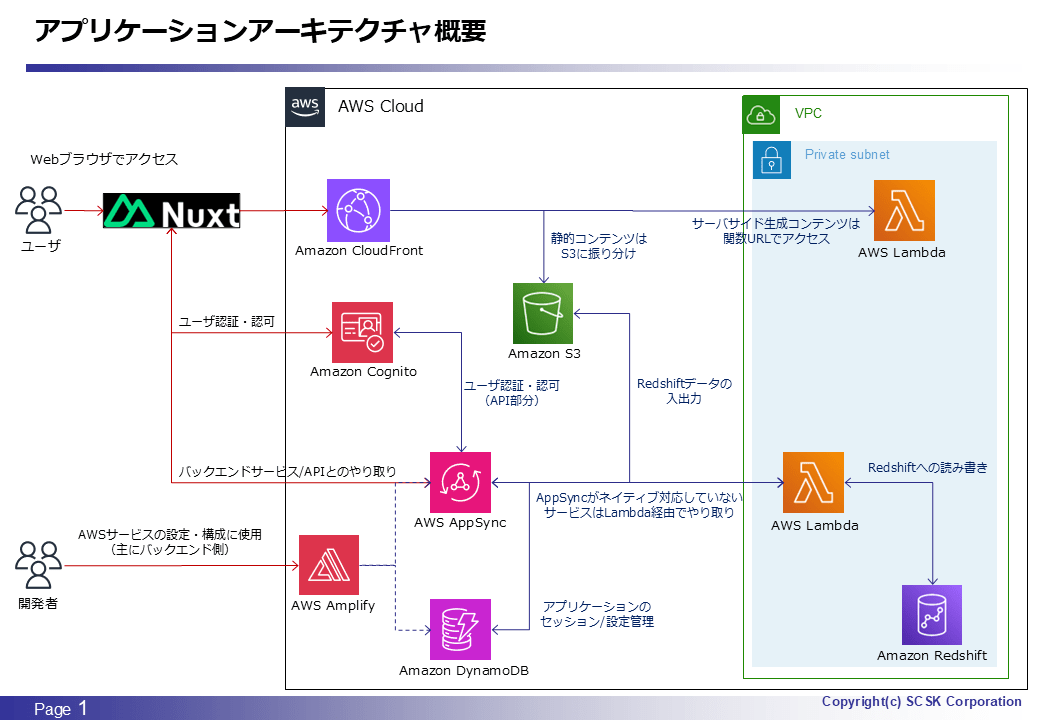
アーキテクチャ図
今回主に言及するのは Redshift のみですが、前回エントリと関連した内容を含むため一応載せておきます。
ポイント1. テーブル定義/データの更新チェック機能
以前のエントリで説明した通り、テーブル定義/データのバージョン管理の要件があること、テーブル定義変更(=DDL操作)についてはアプリケーション外部で実行されることの2点より、アプリケーション側からテーブル定義/データの更新をチェックできる必要がありました。
具体的には、S3 上に出力・配置される対象テーブルの定義/データファイルのハッシュ値を比較することで行っています。対象テーブルの定義/データのバージョン管理を S3 を使用して行っているため、最新のバージョンの定義/データと、チェック実施時の Redshift 上の定義/データを比較して、差異があれば Redshift 側に更新があったことが分かる仕組みです。
が、実はこれは苦肉の策でした。更新チェックを実施するために実質的に Redshift 上の対象テーブル定義/データの全量を取得しているに等しく、コストが大きいためです。通常、本アプリケーション上で対象テーブルを表示する際には、以下のようなロジックを実行しています。
- 対象テーブルの定義/データ更新をチェック
- Redshift 上のテーブルが更新されている場合は、更新チェックの際に S3 上に出力したファイルを最新バージョンとして更新
- 最新バージョンのファイルのテーブル定義/データをアプリケーション上で表示
このようなロジックとした理由はいくつかあるのですが、アプリケーションから対象テーブルを表示する際に毎回 Redshift から全量を取得せずに更新の有無だけをチェックし、更新がない場合はそのまま S3 からテーブル定義/データを取得するようにすることで、レスポンスの向上を狙いの一つとしていました。ところが、実際の挙動としては1.による更新チェックのタイミングで Redshift から毎回全量を取得しているに等しいため、その目論見が崩れてしまっています。逆に言うと、更新チェックはもっと少ないコストで実施できると考えていました。
ポイント2. データバリデーションチェック機能
データのメンテナンス・更新にあたり大事なポイントの1つがデータの整合性を保つことです。データの整合性と一口に言っても様々な観点があるかと思いますが、最も基本的な観点としては列定義や制約(NOT NULL/PK/UK/FK)などのテーブル定義に違反したデータが更新されないかどうかが挙げられると思います。もちろん、本案件事例でも要件に含まれていました。
通常のデータベース (RDBMS) であれば、基本的にデータベース側でバリデーションチェックが行われるため、これらのテーブル定義に違反したデータは更新できないようになっています。このため、ここで言及しているようなデータ整合性を担保するだけであればアプリケーション側での考慮は不要です。
では Redshift の場合はどうかという話ですが、以下 URL の通り NOT NULL 以外の制約は制約として機能しません。定義自体はできますがあくまでもクエリ実行時に Redshift 側で効率的にデータを処理するためのプラン(実行計画)を立てるための参考情報として扱われ、データ自体の制約としては機能しません。つまり、例えば PK 制約が定義されている列に対して重複した値を INSERT することが可能といったように、これらの制約に違反するようなデータを更新することができてしまいます。

一意性、プライマリキー、および外部キーの制約は情報提供のみを目的としており、テーブルに値を入れるときに Amazon Redshift によって強要されるわけではありません。例えば、依存関係のあるテーブルにデータを挿入する場合、制約に違反していても挿入は成功します。ただし、プライマリキーと外部キーはプランニング時のヒントとして使用されます。アプリケーションの ETL プロセスまたは他の何らかのプロセスによってこれらのキーの整合性が強要される場合は、これらのキーを宣言する必要があります。
もちろん(さすがに)列定義に違反するデータは更新できません。以下 URL の通り暗黙の型変換により、意図していないデータ型に変換されて更新される可能性はあるかもしれませんが、このような挙動は(製品/サービスごとの差異はあるとしても) RDBMS でも考慮されるべき内容と思います。

よって、これらの制約に対応するデータバリデーションチェック機能をアプリケーション側で実装する必要がありました。具体的には、バリデーションチェックに失敗した場合はデータの更新を許可せず、バリデーションに失敗した(制約に違反した)データを修正するように画面上で促すようなロジックを実装することで対応しました。
また、このような機能をアプリケーション側で実装する必要があったことから、Redshift 側でチェックしてくれる列定義や一部制約についても同様にアプリケーション側でチェックするようにしました。その方がデータ更新における一連のロジック/フローをシンプルにできることが理由です。Redshift 側でチェックするということは実際に Redshift に対して更新を試行する必要があり、更に試行後のエラー内容をアプリケーション側で解釈してデータバリデーションのエラー画面を出さないといけないことにもなります。データ更新時の承認フローなどとの兼ね合いも考えると、トータルでロジックがかなり複雑になってしまうと判断しました。
まとめ
業務において Oracle を中心とした RDBMS を扱っている期間が長いこともあり、Redshift(もといおおよその DWH)と RDBMS の差異としてはある程度容易に思い浮かぶような内容ではありましたが、アプリケーション実装の観点からまとめておくことも大事と考えたので今回まとめてみました。実際、ポイント1については何となくできるだろう・・みたいにタカを括っていたところできずに、最終的に今の方式に辿り着くまであれこれ試行錯誤することになったりしたので。。このへんの感覚というか勘所はもう少し意識しないといけないかなと感じました。
本記事がどなたかの役に立てば幸いです。