

SCSKの畑です。
これまでのエントリで説明してきた Redshift テーブルデータのメンテナンスアプリケーションにテーブルデータの差分比較機能を実装しているのですが、バックエンド側についてどのように実装したのかを記載してみます。
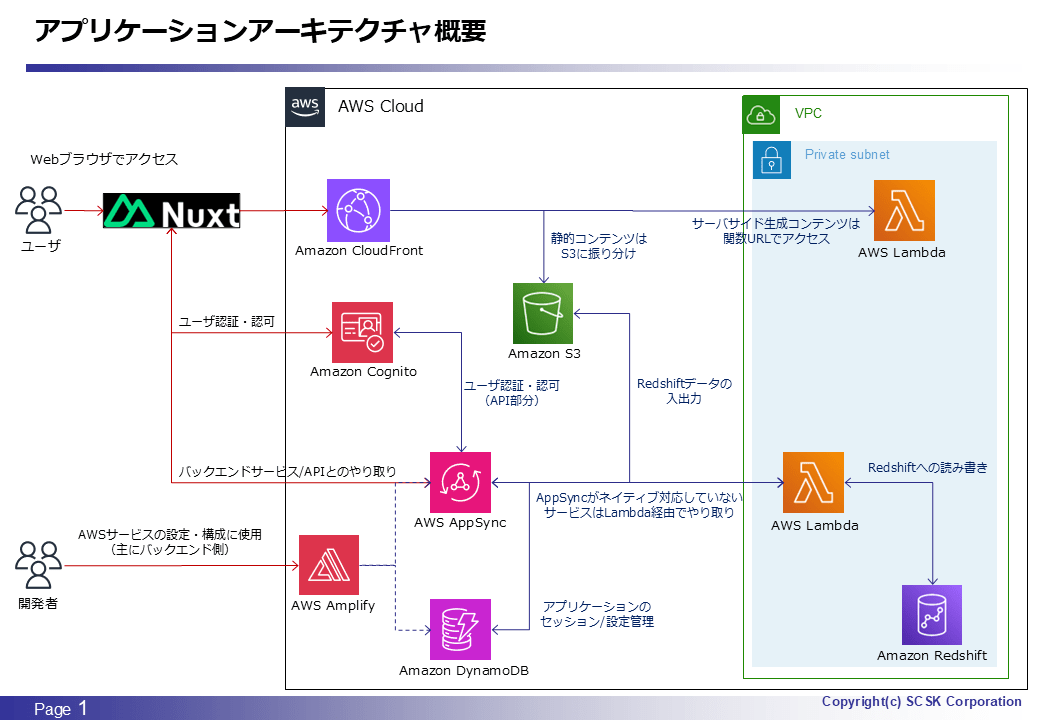
アーキテクチャ図
性懲りもなく今回も。今回はバックエンド側の処理として実装しているため、以下図では AppSync から呼び出される Lambda が対象となります。ただ、Lambda ならではの話みたいなものは今回は正直ないです・・
背景
テーブルデータの差分比較機能については、元々お客さんと詰めた機能要件の一つにありましたので実装は規定路線でしたが、フロントエンド/バックエンドのどちらで実装するかというのがちょっとした考えどころでした。本アプリケーションにおけるテーブルデータの差分比較機能は、
- アプリケーション上でユーザが編集したデータと編集前のデータを比較
- 異なるバージョン間のテーブルデータを比較
の2パターンで使用されますが、前者の方が使用頻度は高いと思われること、及び(当然ながら)ユーザはアプリケーション上でテーブルデータを編集することの2点より、当初はフロントエンド側で実装する方針としました。しかし、具体的にどのようなアプローチで実装するのかなかなか定まりませんでした。
まず、少し前のエントリで紹介した Tablator 上で編集した項目(セル)の情報を保持できるためそれをそのまま使用しようかと考えていましたが、ライブラリの仕様上削除した行データ&外部ファイルからインポートしたデータの場合は対象とならないことが分かりました。また、異なるバージョン間のテーブルデータを比較する場合は実質的に S3 上のテーブルデータ同士を比較する処理となり、Tablator の機能は使用できないため見送ることに。
よって、真っ当に2つのテーブルデータを比較するような処理をフロントエンドでどう実装するかを考えたのですが、Javascript(Typescript)でその手の処理を実装したことがなかったため、ライブラリや比較手法の調査でこれという正解が見つかりませんでした。元々 Python の pandas ライブラリについては過去案件などで使い慣れていたため、pandas ライクに使用できるライブラリが良さそうということで調べたところ danfo.js なるものを見つけました。

使い勝手も良さそうだったのですが、実はこの調査の過程で pandas であれば簡単に差分比較できる方法を見つけてしまっており・・残念ながらその方法が使えなさそうだったため、その分のロジックについて自前で実装することを考慮するとバックエンド側で Python/pandas を使用して実装してしまう方がトータルで効率良いのではないかということで、バックエンド側で実装する方針に変更しました。また、差分比較処理自体は相応に重い処理であるため、フロントエンド(クライアント)側で実装した場合の影響を憂慮したことも理由の一つです。バックエンド側で実装する分には、(極論) Lambda に頑張ってもらえれば良いだけなので・・
なお、バックエンド側で差分比較を実装するにあたり、フロントエンド側で編集したテーブルデータをバックエンド側に持ってくる処理が追加で必要となりましたが、ちょうど編集中のデータを S3 上に一時保存するような機能を実装したところだったため、同機能と合わせて差分比較を実施するようにすることで問題なく実装できました。異なるバージョン間のテーブルデータ比較については先述した通りS3 上のテーブルデータ同士を比較する処理であり、Lambda 上から直接処理できたため問題ありませんでした。
pandas を使用した実装方法
ということで本題なのですが、pandas.DataFrame.merge の indicator 引数を使用することでテーブルデータの差分比較を容易に実現することができました。

例として以下のような2つのテーブル間での差分比較を考えてみます。table_1 を編集前のデータ、table_2 を編集後のデータと想定し、同テーブルにおける PK 列を「pk」列とします。
[table_1]
pk col_1 col_2 col_3
row_0 1 2 3 4
row_1 11 12 13 14
row_2 101 102 103 104
[table_2]
pk col_1 col_2 col_3
row_0 2 3 4 5
row_1 11 12 13 14
row_2 101 102 1030 1040
よって、差分比較の結果としては、
- table_1 の 1行目:table_1 にのみ存在するデータ(=編集で削除された行データ)
- table_2 の 1行目:table_2 にのみ存在するデータ(=編集で追加された行データ)
- table_1/table2 の 3行目:table_1 の 3行目の「col2」「col3」列の値が変更されたデータ
のように差分が検出されることを期待しています。
具体的な実装例は以下の通りです。df_table_1 及び df_table_2 にそれぞれのテーブルに対応した DataFrame が定義されている前提として、DataFrame.merge で差分比較を実施しています。この関数自体は2つのテーブルを結合(マージ)する関数であり、結合条件は on 引数で、結合方法は how 引数で示されます。よって、以下の実装例は全ての列を結合条件とした外部結合処理となります。
import pandas as pd
df_table_1 = pd.DataFrame(
[[1, 2, 3, 4], [11, 12, 13, 14], [101, 102, 103, 104]],
columns=['pk', 'col_1', 'col_2', 'col_3'],
index=['row_0', 'row_1', 'row_2']
)
df_table_2 = pd.DataFrame(
[[2, 3, 4, 5], [11, 12, 13, 14], [101, 102, 1030, 1040]],
columns=['pk', 'col_1', 'col_2', 'col_3'],
index=['row_0', 'row_1', 'row_2']
)
df_compared = pd.merge(df_table_1, df_table_2, on=['pk', 'col_1', 'col_2', 'col_3'], how='outer', indicator=True)
すると、実行結果として以下のような DataFrame が得られます。この _merge 列の内容が実質的に差分比較結果を示しており、それぞれ以下のような意味となります。つまり、both 以外の行については何らかの差分があるということになります。
- both:両方のテーブルに存在している行データが一致している行
- left_only:左側のテーブルにのみ存在している行
- 本実装例では table_1 が該当
- right_only:右側のテーブルにのみ存在している行
- 本実装例では table_2 が該当
pk col_1 col_2 col_3 _merge 0 1 2 3 4 left_only 1 2 3 4 5 right_only 2 11 12 13 14 both 3 101 102 103 104 left_only 4 101 102 1030 1040 right_only
実行結果を見ますと、想定される差分比較結果の項目で示した内、1. と 2. の項目については想定通りに検出されていることが確認できます。一方で 3. の項目については left_only と right_only の両方が出力されています。
これは先述した外部結合のロジックを踏まえると自明なのですが、全列のデータを比較している以上 table_1 と table_2 で異なる行データとして出力されることから、即ち left_only と right_only の両方が出力されている行はデータの一部が変更されていることが分かります。ただ、この実行結果自体からはプログラム上でそれを簡単に判断することができません。よって、行データを一意に区別するための情報である PK 列で実行結果を GROUP BY することにより、各行ごとの差分比較結果を得ることができます。以下変更後のコードとなります。
import pandas as pd
df_table_1 = pd.DataFrame(
[[1, 2, 3, 4], [11, 12, 13, 14], [101, 102, 103, 104]],
columns=['pk', 'col_1', 'col_2', 'col_3'],
index=['row_0', 'row_1', 'row_2']
)
df_table_2 = pd.DataFrame(
[[2, 3, 4, 5], [11, 12, 13, 14], [101, 102, 1030, 1040]],
columns=['pk', 'col_1', 'col_2', 'col_3'],
index=['row_0', 'row_1', 'row_2']
)
df_compared = pd.merge(df_table_1, df_table_2, on=['pk', 'col_1', 'col_2', 'col_3'], how='outer', indicator=True).query(f'_merge != "both"').groupby(['pk'])
for pk_cols, group in df_compared:
print(f'pk_cols: {pk_cols}')
print(group)
その結果、以下のように PK の値ごとに差異のある行データがそれぞれ取得できていることが分かります。
pk_cols: (1,) pk col_1 col_2 col_3 _merge 0 1 2 3 4 left_only pk_cols: (2,) pk col_1 col_2 col_3 _merge 1 2 3 4 5 right_only pk_cols: (101,) pk col_1 col_2 col_3 _merge 3 101 102 103 104 left_only 4 101 102 1030 1040 right_only
もちろんこのままでは3.のパターンについてどの列のデータに差異があるのか分からないため、Lambda 上では差異検出用のロジックを組んだ上で追加された行・削除された行・変更された行の3パターンに分けて最終的に JSON 形式で情報を出力するようにしていますが、そのあたりの実装は本情報を扱うアプリケーション/処理によって適宜変更されるものと思います。
なお、本実装の制約事項として、ロジック上テーブル定義(列定義)の異なる2つのデータを比較した場合はエラーが出力されてしまい比較できません。本アプリケーションにおいて列定義の変更はスコープ外としておりその観点では考慮の必要がありませんでしたが、アプリケーション外での列定義変更についてはユースケース上あり得るため、Lambda 上の実装では DataFrame.merge の実行前に列定義が同一であることを確認するようにしています。
まとめ
本案件事例ではアプリケーション内の一機能として実装していますが、例えばデータベースの移行時や ETL/ELT 関連処理時においてデータベース外でテーブルデータの差分比較を実施したいケース自体はこれまでも度々あったため、備忘も兼ねてまとめてみた次第です。もちろん、データベース内で比較してしまうのが、処理速度やリソース面の観点も含めて一番手っ取り早い方法かと思いますが、ファイルベースで比較したいという機会も意外と多かったりするので・・
本記事がどなたかの役に゙立てば幸いです。