
こんにちは、広野です。
AWS re:Invent 2025 で、Amazon S3 Vectors が GA されました。

以前は RAG 用のベクトルデータベースとして Amazon OpenSearch Service や Amazon Aurora など高額なデータベースサービスを使用しなければならなかったのですが、Amazon S3 ベースで安価に気軽に RAG 環境を作成できるようになったので嬉しいです。
それを受けて、以前作成した RAG チャットボット環境をアレンジしてみました。
内容が多いので、記事を 3つに分けます。本記事はアーキテクチャ概要編です。
つくったもの
こんな感じの RAG チャットボットです。
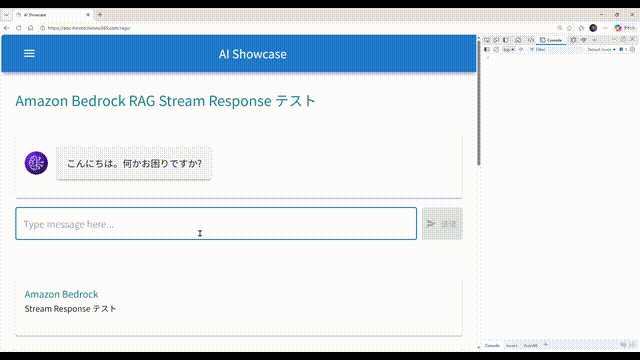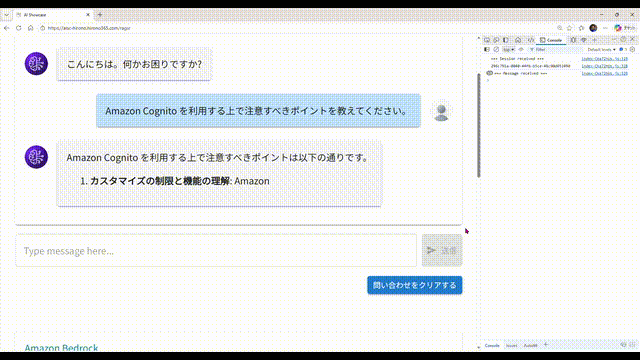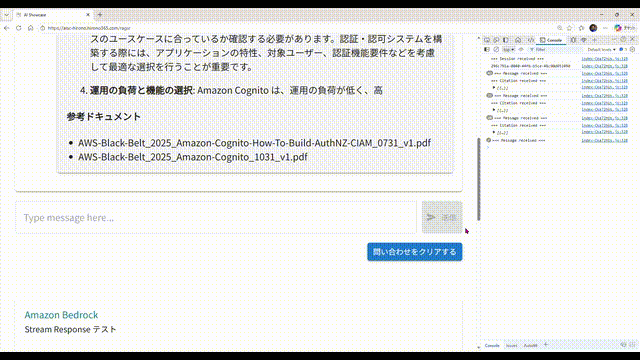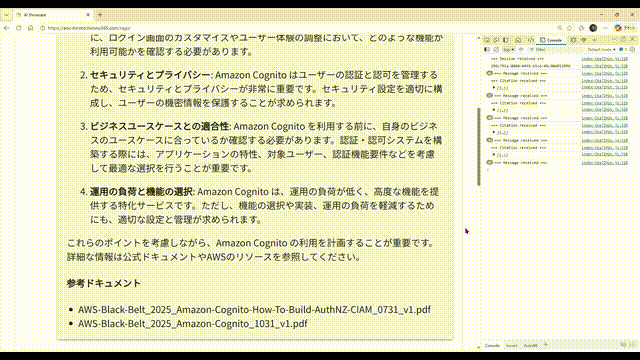
- 画面から問い合わせすると、回答が文字列細切れのストリームで返ってきます。それらをアプリ側で結合して、順次画面に表示しています。
- 回答の途中で、AI が回答生成の根拠にしたドキュメントの情報が送られてくることがあるので、あればそのドキュメント名を表示します。一般的には親切にドキュメントへのリンクも付いていると思うのですが、今回は簡略化のため省略しました。
- このサンプル環境では、AWS が提供している AWS サービス別資料 の PDF を独自ドキュメントとして読み込ませ、回答生成に使用させています。
ふりかえり・過去の関連記事
だいぶ前になりますが、Agents for Amazon Bedrock を使用した RAG チャットボットを作成したことがありました。

- 当時は Agents for Amazon Bedrock 経由でないと Amazon Bedrock Knowledge Bases にアクセスできず、回答待ち時間が長かったです。
- ベクトルデータベースは Amazon Aurora Serverless なので比較的安価でしたが、データベース構築のオーバーヘッドがありました。
現在は Agents for Amazon Bedrock なしで Amazon Bedrock Knowledge Bases に直接問い合わせができるようになっています。また、冒頭で紹介した通りベクトルデータベースとして Amazon S3 が使用できるようになりました。レスポンスもかなり速くなりました。
Amazon Bedrock の LLM に単純に問い合わせるだけのチャットボットは、昨年度の最新アーキテクチャで作成しておりました。このアーキテクチャをそのまま活用し、過去の RAG チャットボットを改善したものを作成します。
アーキテクチャ
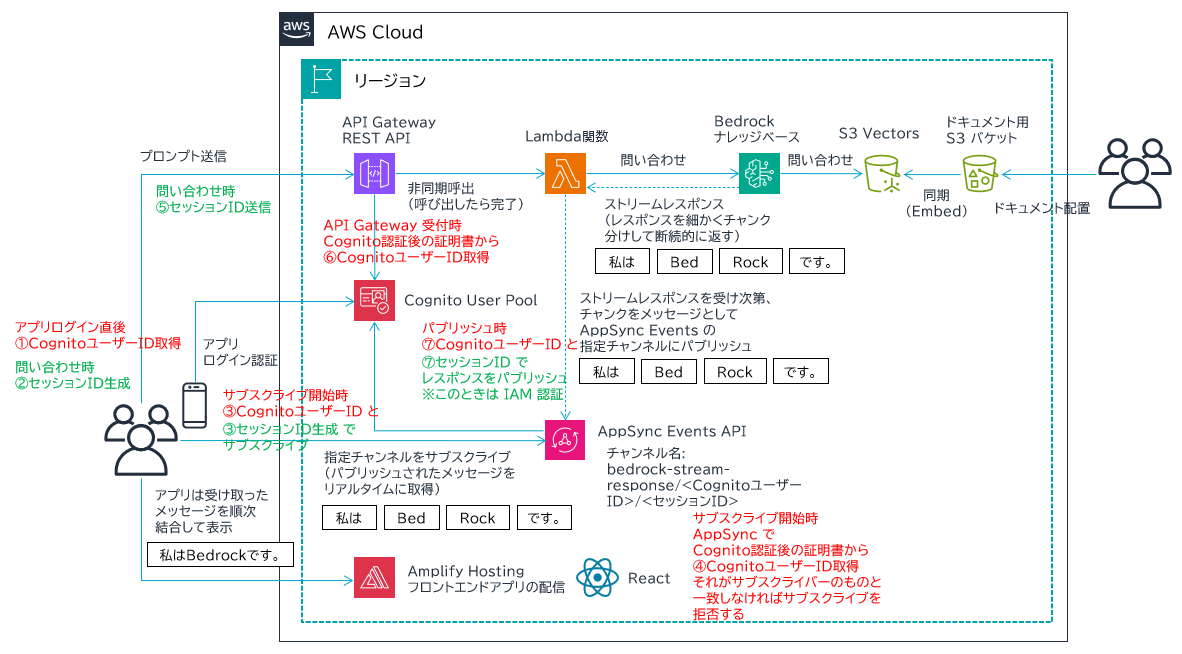
- 図の左側半分、アプリ UI 基盤は以下の記事と全く同じです。お手数ですが内容についてはこちらをご覧ください。
- 図の右側半分、Lambda 関数から Bedrock ナレッジベースに問い合わせるところを今回新たに作成しています。
- まず、RAG に必要な独自ドキュメントを用意し、ドキュメント用 S3 バケットに保存します。
- S3 Vectors を使用して、Vector バケットとインデックスを作成します。
- これら S3 リソースを Amazon Bedrock Knowledge Bases でナレッジベースとして関連付けます。
- それができると、ドキュメント用 S3 バケットのドキュメント内容をベクトルデータに変換して S3 Vectors に保存してくれます。これを埋め込み (Embedding) と言います。埋め込みに使用する AI モデルは Amazon Titan Text Embeddings V2 を使用します。
- Bedrock ナレッジベースが完成すると、それを使用して回答を生成する LLM を指定します。今回は Amazon Nova 2 Lite を使用します。Lambda 関数内でパラメータとして指定して、プロンプトとともに問い合わせることになります。
- フロントエンドの UI は React で開発します。
細かい話
この RAG チャットボットを作成するにあたり、苦労、工夫した点を挙げます。かなり細かい話です。上記のざっくりとしたアーキテクチャ図では表せない補足事項です。
継続問い合わせ時のセッション管理
いわゆる生成 AI チャットボットは、初回問い合わせの回答以降は AI が前の会話内容を覚えている状態で回答を考えてくれることが一般的です。
Amazon Bedrock Knowledge Bases はネイティブにその機能を持っていて、問い合わせを過去の問い合わせと関連付けさせるために会話にセッション ID を関連付けます。セッション ID は初回問い合わせ時に生成されたレスポンスに含まれ、2回目以降の問い合わせ時には問い合わせのパラメータに含める必要があります。

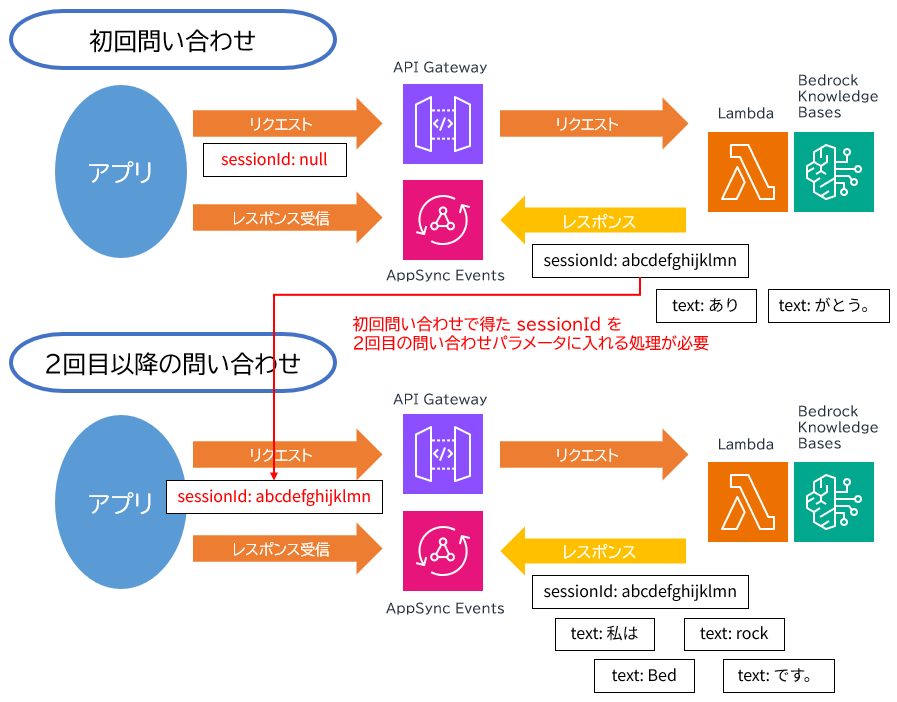
ややこしいですが、Amazon Bedrock Knowledge Bases が問い合わせを管理するセッションと、AWS AppSync Events チャンネルをサブスクライブするためのセッションという 2つのセッションがあり、それぞれアプリ側とバックエンド側で共通認識を持つ必要があります。一連の問い合わせであれば 2つのセッション ID をそれぞれ同じものを使用する必要があり、問い合わせをリセットする (新たな新規問い合わせにする) ときには両方のセッション ID をリセットする必要があります。
参考ドキュメントの取り扱い
参考ドキュメントの情報 (citation と呼びます) は Amazon Bedrock Knowledge Bases が問い合わせに対する回答文を作成し chunk 分けして五月雨式に送信してくる途中に入ってきます。ドキュメント名は重複することがあります。回答文章内のいくつかの異なる文面にそれぞれ参考ドキュメントがあったとしても、それらが同じドキュメントである可能性があるからです。
そのため、生成された citation 情報の重複排除と、受け取ったら UI に表示する処理をリアルタイムに行う必要があります。これをバックエンド側で一時的にバッファして処理させようとしてもうまくいかなかったので、アプリ側で処理しています。バックエンド側はとにかくアプリに忠実に chunk を送りつけることに専念させています。
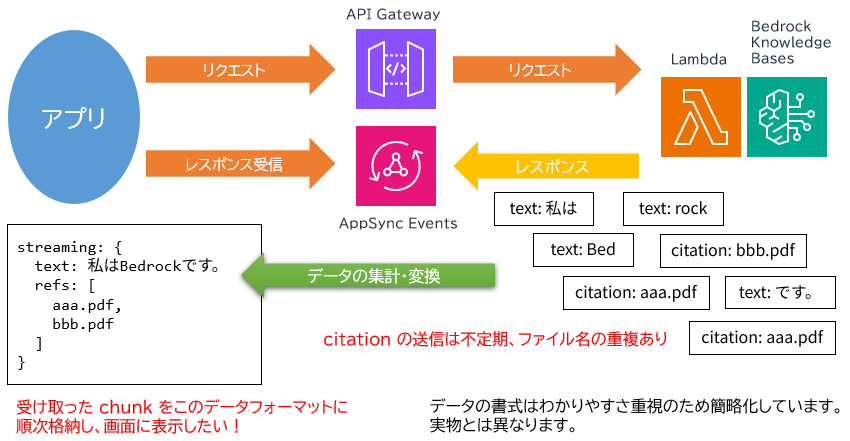
当初、回答文字列 (text) と参考ドキュメント (citation) を React 別々の変数 (React 的には State) に格納していましたが、それだと画面更新に競合が発生し、うまくいきませんでした。text と citation は同じ一連のレスポンスストリームとして送られてくるので、同じストリームによる画面更新は 1つの State (上の図では streaming) で管理するべきと考えました。
実装について
まず、この基盤のデプロイについては以下の Amazon Bedrock 生成 AI チャットボットの環境がデプロイできていることが前提になっています。そこで紹介されている基盤に機能追加したイメージです。

新たな RAG チャットボットの基盤については実装編、アプリ UI については UI 編の続編記事でそれぞれ紹介します。

まとめ
いかがでしたでしょうか?
Amazon Bedrock Knowledge Bases で RAG チャットボットを開発するときのアーキテクチャを紹介しました。
本記事が皆様のお役に立てれば幸いです。