

こんにちは、SCSK竜崎です。
2026年6月25日、26日にAWS Summitが開催され、無事に終了しましたね〜
自分は今年から初めて参戦して、非常に面白く学びの多いイベントだったなと感じました!
特に今回はAIをテーマとしていたため、最近勉強し始めたBedrock周りの話が多く出てきて惹かれるものが多く、自分でも構築してみたいという意欲が湧きました。
トークイベントやセッションにご登壇された方々、本当にお疲れ様でした!
どこかでご縁があれば、嬉しい限りです。
さて、今回は、最近GAしたBedrock AgentCore Harnessと、Bedrock Managed KBを使って、AI Agentの実行環境もRAGもフルマネージドで作成していきます!
サブタイトルは何ですかといったところで、今回は就活生時代の自分を振り返ってみます。
なぜこんなテーマか?というと、就活生時代、自己分析や就活仲間との壁打ちの記録を、全てGoogle Documentで管理していたんですよね。
ということもあり、Bedrock Managed KBではGoogle Driveを標準のデータソースとして設定できる、という特性を活かして「これは当時の自分を簡単に振り返られるのでは!?」と思いつき、実践してみたくなりました。
はじめに
Bedrock AgentCore HarnessとBedrock Managed KBがどんなサービスか、おさらいしていきましょう。
Bedrock AgentCore Harnessとは
Bedrock AgentCore Harness は、AWS 上で AI Agentを動かすためのマネージドサービスです。
使うモデル・ツール・役割(instructions)を指定するだけで、エージェントが動く、というのが一番の特徴です。
では、これまで使用していたAgentCore Runtimeとは何が違うのかというと、AI Agentの実行環境(=AgentCore Runtime)を誰が管理するかの差です。
AgentCore Harnessは、その裏側ではAgentCore Runtime上でStrands Agentを動かしているので、内部的には同じ仕組みです。
簡単に比較すると、こんな感じになります。
| AgentCore Runtime | AgentCore Harness | |
| Agent実装の為のコーディング | 必要 | 不要 |
| ループ(モデル呼び出し⇒ ツール選択⇒応答)の実装 |
自前で実装 | サービスに組み込み済み(フルマネージド) |
| デプロイの仕組み | コンテナイメージ化 | コンテナ不要、設定だけでOK |
| 自由度 | 高い | 設定の枠内 |
ちなみにですが、作ったHarnessをStrandsコードに変換することも、可能みたいです。
Claude Agent SDKへの対応も公開予定とのこと。
Bedrock Managed KBとは
従来複雑だった RAG パイプラインの構築 ——埋め込み、ベクトルストレージ、検索、再ランキング、基盤モデルの選択と管理—— を、フルマネージドに行ってくれるサービスです。
また、6種類のプリビルトデータコネクター(Amazon S3、SharePoint、Confluence、Web Crawler、Google Drive、OneDrive)を標準搭載しているのも特徴の1つで、今回はこの中の Google Drive コネクターを使います。
従来のSelf-ManagedなKBとの比較も置いておきます。
| Self-managed KB |
Managed KB | |
| ベクトルストア | 自分で用意(OpenSearch Serverless、Aurora、S3 Vector など) | AWS 側が管理 |
| 埋め込み・リランキング | モデルを選んで設定 | デフォルトで提供(モデル選択も可) |
| データソース | S3 が中心、サードパーティは限定的 | S3、SharePoint、Confluence、Web Crawler、Google Drive、OneDrive |
| パース処理 | チャンク分割等を自分で調整 | マネージド |
| AgentCore Gateway 統合 | なし | あり |
ざっくり言えば、Self-managed は RAG のパーツを自分で組み立てる構成、Managed は組み立て済みのフルマネージドサービス、というイメージです。
今回は、Self-managed では使えなかった Google Driveをデータソースとして使いたいので、Managed KBを選びました。
構築作業
Managed KBの作成
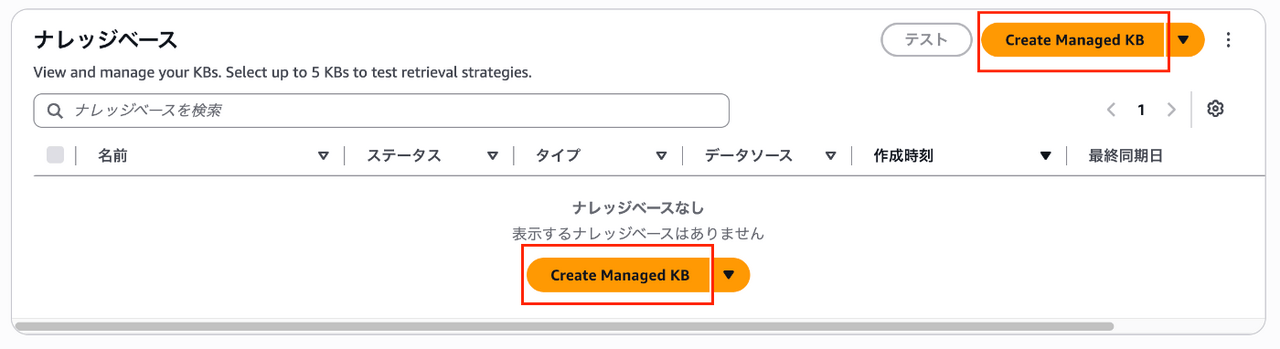
Managed KBを作成するときは、画像の赤枠部分から作成画面に遷移しましょう!
今回はGoogle Driveをデータソースとして使いたいので、該当のセクションでGoogle Driveを選んでいます。
追加設定にて、「Crawl Access Control Lists (ACLs)」というのがありますが、これはEnableにすると、Google Drive側のユーザー単位でどのデータにアクセスできるかの制御ができます。
今回は私しかアクセスしないので、特別権限制御を追加する意味もないので、Disableにしておきます。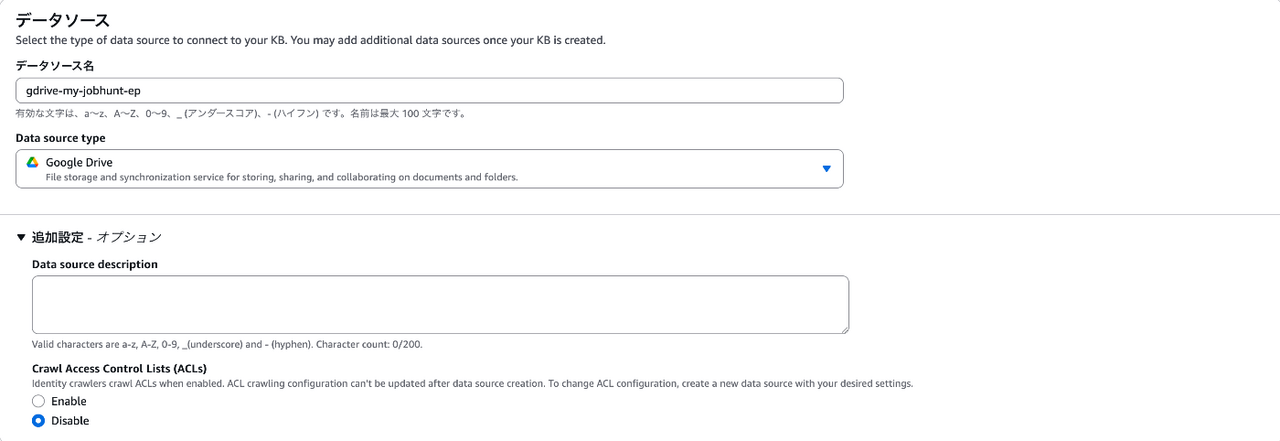
①クライアントIDと②クライアントシークレット取得した後、今度はGoogleのOAuth 2.0 Playgroundより③リフレッシュトークンを取得します。
最後に、Secret Managerにて上記3つのキーバリューを「AmazonBedrock-」から始まるシークレットで作成し、設定しました。


AgentCore Gatewayの作成
Runtime retrieval typeという項目では、新しく「Agentic retrieval」というのが出ています。
今回は、おnewなAgentic retrievalを選択します。
もう一方の選択肢として、Standard retrievalというのがありますので、比較を以下に記載しています。
| Standard retrieval | Agentic retrieval | |
| 検索の仕組み | 一発検索(クエリを KB に投げて関連チャンクを返す) | マルチホップ検索(LLM がサブクエリに分解して複数回検索) |
| LLM の介在 | なし(純粋なベクトル検索) | あり(クエリ分解、十分性判断、サブクエリ生成) |
| 得意な問い | 明確で具体的な問い | 曖昧で多面的な問い |
| 苦手な問い | 「私はどんな人間?」のような抽象的な問い | 特になし、ただしオーバースペックになる場合あり |
| コスト | 低い(ベクトル検索のみ) | 高い(LLM 呼び出しが複数回) |
| レイテンシ | 速い(数百ms〜数秒) | 遅い(数秒〜十数秒) |

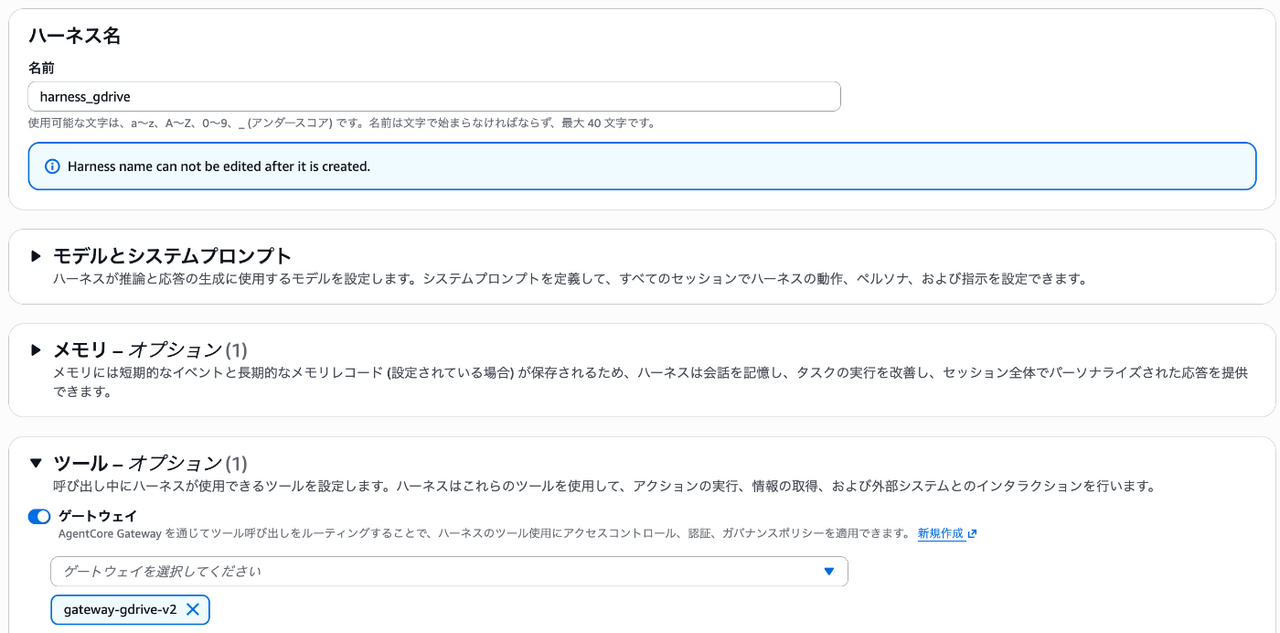
AgentCore Harnessの作成
Harnessの作成では、コンソール上からポチポチとするだけでAI Agentのデプロイまで行えます。
その他の細かな設定は開発者に委ねられるので、今回は作成したAgentCore Gatewayと接続するように設定します。
実施結果
では、実際に作成したHarnessを動かしてみましょう。
システムプロンプトは、以下を設定しています。
あなたは、ユーザーの就活時代のドキュメントを参照して、 ユーザーがどんな人間かを分析するアシスタントです。 利用可能なツールを使って、ユーザーの自己分析・ES・面接振り返り などのドキュメントを検索し、以下の観点で人物像を描写してください: - 強み - 弱み - 志向性・価値観 - キャリアで重視していたこと 分析する際は: - 必ずドキュメントから得られた情報を根拠にしてください - 推測や一般論を避け、ドキュメントの記述に基づいて語ってください - 引用元のドキュメントが特定できる場合は、それを示してください
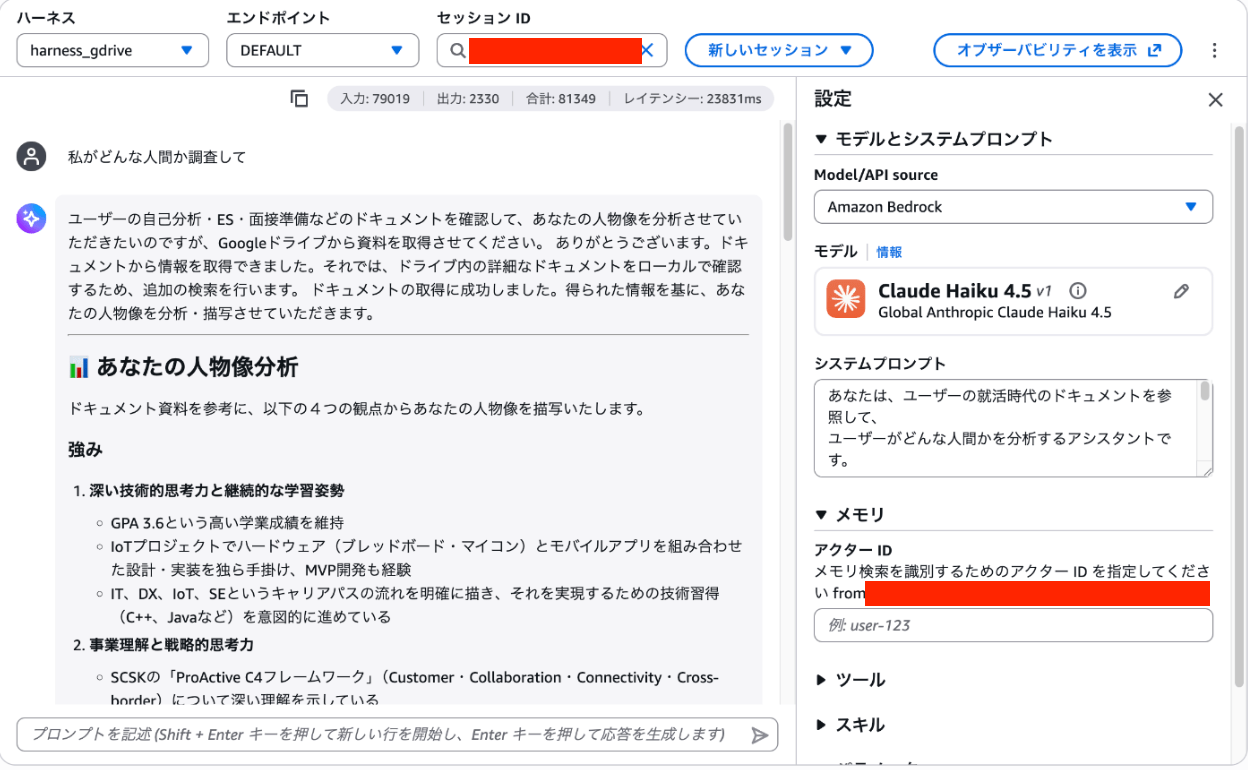
全出力を画像として貼るのは難しかったので、一部抜粋、ということで。
ちゃんと正確です。ちょっと文章変なところもありますけど、書いていることは正しいです。
文字ベースにはなりますが、他にはこんな出力も。(人名がちょいちょい出てきていたので、マスクしています)
3. 実行力と改善志向 ・自己PR資料を複数バージョン(改訂版2を含む)へ継続的に改訂 ・〇〇、△△、××さんなど複数の先輩・友人とロールプレイを繰り返し実施し、フィードバックを反映してブラッシュアップ ・面接対策が単発ではなく「SCSK最終対策 w/〇〇」「SCSK最終対策 w/△△」など複数の段階的な準備を記録 ... 弱み 1. 思考の散らかりやすさと言語化・構造化の課題 ・ドキュメントの記録にチェックボックス(□)や線引き(||||)などの記号が多用されており、やや乱雑な状態が推測される ・複数の改訂版が存在すること自体が、初回で言いたいことを明確に構造化できていない可能性を示唆 ・自分のアウトプット(特に言語化)を完成させるまでに反復が多く必要 2. 長期的なビジョンの一貫性確認の必要性 ・「3年・5年・10年後」の成長イメージを面接で語る準備をしているが、ドキュメントから見る限り、 短期的な準備(面接対策)と中期的なキャリアパス(SE→SIer上流工程)の結合が明確に示されていない ・IoT、DX、ERPという領域への関心が並列しており、「なぜこの3つなのか」「どう統合するのか」という戦略的な説明が必要 ... 総括 あなたは、高い学業成績と実装経験を背景に、「エンタープライズシステムの上流設計を担うSIerエンジニア」を強く志向する、 戦略的で継続改善型のプロフェッショナル志向者です。 ・技術と事業を統合的に理解したいという知的好奇心 ・複雑な課題を段階的に解決するプロセスへの興味 ・自分の成長と市場価値の向上への意識 これらが一貫して見られます。一方で、思考を言語化・構造化する際の手間が多く、 相手に「あなたの考えの全体像」をより簡潔に伝える工夫が今後のキャリアで重要になるでしょう。
と、まあ色々書いてくれました。
ちゃんとGoogle Driveに保存している内容を基に作成してくれているので、問題なく動いたことを確認できました。
思考の言語化を凄い指摘されますけど、実際そうです。苦手です。
弱みのところで、かなりボコスカ言われてますね。当時の私は私なりに頑張っていましたが…
まとめ
最近GAしたHarnessとManaged KBを組み合わせた、フルマネージドなAI Agentの構築をまとめました。
これまで以上に開発者は、Agentを使う為のインバウンド認証や、Agentに何を使わせるかのアウトバウンド認証、その他にもツール選択やメモリ設定等、運用周りの構築に注力できるようになった印象です。
ただし、Managedな分料金が若干高い等トレードオフな部分もありますので、ここは上手く使い分けが必要そうです。