
こんにちは、SCSK林です!
今回は、AWS、Snowflakeで実現したニアリアルタイムデータ連携について解説します。
本記事では、実際に構築した例をベースにアーキテクチャ選定の背景と、構成や技術的に気をつけるポイントについて共有していきたいと思います。
構成の背景(いわゆる要件)
今回の主要件は、オンプレミスのシステムから出力される業務データを、AWSを経由してSnowflakeへ連携し、数分以内(ニアリアルタイム)に分析可能にすることでした。
主な要件と制約は以下の通りです。
- セキュリティ:秘匿性の高いデータを扱うため、インターネット経由の転送は不可。閉域網のみを通すこと。
- データ特性:1リクエストあたり約10MB(圧縮前)。頻度は1日100件程度だが、データの欠損は許されない。
- クライアント制約: 送信元システムはHTTPリクエストの送出のみ対応。
- 既存資産:組織内で実績のあるSnowflake連携用スクリプト(Shell)を流用したい。
アーキテクチャ概要
データ取り込み処理 :
- Client (On-prem) → Direct Connect → VPC Endpoint (Interface) → Amazon API Gateway (HTTP API) → AWS Lambda
一時保存 :
- Amazon S3 (Staging Bucket)
ロード処理 :
- S3 Event Notification → AWS Lambda → Snowflake (COPY INTO)
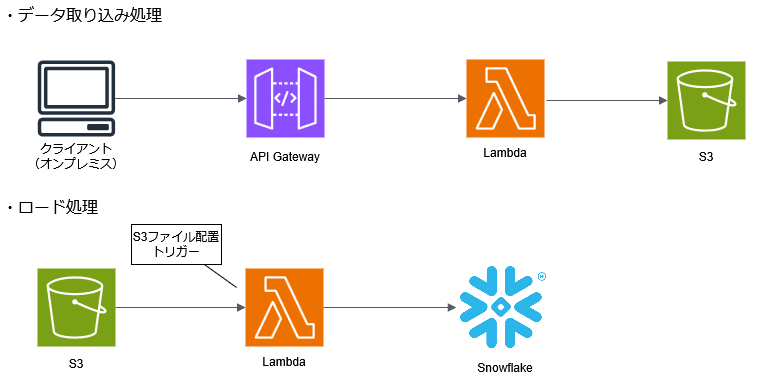
このアーキテクチャのポイントは、「データ受信」と「データ処理」をS3を介して完全に切り離した点にあります。
クライアントからのデータ受信を行うLambda(データ取り込み処理)は、データの検証とS3への保存のみを行い、即座にレスポンスを返します。一方、Snowflakeへのロードを行うLambda(ロード処理)は、S3イベントをトリガーに非同期で実行されます。
これにより、仮にSnowflake側の処理に時間がかかったとしても、クライアント側のHTTP通信がタイムアウトすることはありません。
アーキテクチャのポイント
セキュリティ要件(閉域網)の実現
オンプレミスからのHTTPリクエストを安全に受け取るため、API Gatewayの前段にInterface VPC Endpoint (PrivateLink) を配置しました。
Private API Gatewayを使用する選択肢もありましたが、今回はネットワーク経路を厳密に制御するため、VPC Endpointのリソースポリシーを活用しました。これにより、特定のDirect Connect経由のトラフィックのみを許可し、それ以外のアクセスをネットワークレベルで遮断することを実現しています。
Lambdaの6MB制約とその回避
今回、技術的なハードルとなったのが、AWS Lambdaのペイロード制限です。
- API Gatewayの制限:最大10MB
- Lambda(同期呼び出し)の制限:最大6MB
クライアントから上記制限を越えるデータが送られてくると、そのままではLambdaに引き渡す段階で 413 Request Entity Too Large エラーが発生してしまいます。 これを回避するために、S3署名付きURLを発行してクライアントから直接S3へアップロードさせる方式も検討しましたが、クライアント側の実装負荷が複雑になるため、アーキテクチャは変更せず「データ圧縮」で解決する方針を決定しました。
今回は、クライアント側でデータをGZIP圧縮することで、ペイロードサイズを数MBまで削減し、これによりLambdaの6MB制限をクリアしました。ただ、そういうわけにも毎回いかないと思いますので同様の構成を検討する際はぜひご注意ください。
「取り込み」と「ロード処理」の責務の分離による耐障害性の確保
今回は、API Gatewayから直接Snowflakeへデータを流し込むのではなく、S3を境界として「Ingest(取り込み)」と「Process(ロード処理)」の責務を明確に分離しました。
-
データ取り込み処理層 (同期):
- 役割: クライアントからのリクエストを高速に受け付け、S3へ永続化することだけに集中する。
- 効果: Snowflake側の状態(一時的なパフォーマンス低下など)の影響をクライアントに与えない。クライアントへは即座に
200 OKを返却し、接続タイムアウトのリスクを排除。
-
データロード層 (非同期):
- 役割: S3へのオブジェクト作成イベントをトリガーに、非同期でSnowflakeへの
COPY INTOを実行する。 - 効果: 重い処理(DB接続・ロード)をここへ集約。もしロード処理が失敗しても、データはS3上に「ファイル」として安全に残っているため、データロード層(クライアント)に影響を与えることなくリトライやリカバリが可能。
- 役割: S3へのオブジェクト作成イベントをトリガーに、非同期でSnowflakeへの
この「S3をバッファとした疎結合アーキテクチャ」を採用したことで、クライアントに対するレスポンス性能(レイテンシ)を一定に保ちつつ、バックエンド処理の安定性を高めることを実現しました。
運用を見据えた設計
データ連携基盤においてもっとも考慮が必要なことは「データのロスト」です。
今回は、万が一Snowflakeへのロードが失敗した場合(データフォーマット不正やウェアハウスの一時的な問題など)に備え、以下の仕組みを導入しました。
- エラーハンドリング : Lambda内で例外をキャッチした場合、対象のオブジェクトをS3上の「Error」フォルダへ移動(Move)。
- 監視 : エラーフォルダへの配置をトリガーに、管理者へ即時通知。
これにより、失敗したデータが「どこにあるか分からない」状態を防ぎ、リカバリが必要なデータを明確に分離する運用を設計しました。
まとめ
今回の構成では、マネージドサービスベースのデータ連携基盤(ニアリアルタイム)を実現しました。
データ連携は頻度をあげることでより難易度が増していきます。
今回の構成、事例がどなたかのお役に立つと幸いです。