

みなさん、こんにちは。 SCSKの石井です。
前回は、AIの歴史について触れて世代別について皆さんに分かりやすくご紹介させて頂きました。今回は現在のAI(DL)ディープラーニングの隆盛の礎を築いた
「真の先駆者の一人」として、世界中で再び脚光を浴びているAI巨匠と呼ばれる、レジェンドをご紹介します。
世界中で使われている「QRコード」を開発したのが、日本のデンソー(現デンソーウェーブ)の原昌宏(はら まさひろ)さんであるように、ディープラーニングを含むAIの歴史においても、実は日本人が決定的な先駆者として名を残しています。 その方が「甘利 俊一(あまり しゅんいち)」さんです。
一目でもお会いしてみたいものです。


「現在の生成AIブームやディープラーニング(深層学習)の熱狂は、突然変異的に現れたものではない。」――これは、数理情報科学、そしてニューラルネットワーク(NN)研究を黎明期から支え続けてきた世界的な巨頭・甘利俊一先生の足跡を辿れば、確信へと変わる事実です。本記事では、AI界の生ける伝説である甘利氏の技術的業績を深く掘り下げるとともに、その数理思想がいかにして現代の最先端セキュリティ技術へと脈々と受け継がれているのか、個人的な技術知見を交えて徹底的に考察します。
AIレジェンド甘利俊一がもたらした「数理ニューロサイエンス」の衝撃
現代のエンジニアの多くは、ディープラーニングを「大量のデータと潤沢なGPUリソースによって駆動する経験則的な最適化手法」として捉えがちです。
しかし、半世紀以上も前、まだコンピュータが極めて非力だった時代に、ニューラルネットワークを純粋な「幾何学」の対象として数理モデル化した人物がいます。
それこそが、東京大学名誉教授であり、理化学研究所脳科学総合研究センター長などを歴任された甘利俊一氏です。
甘利氏の研究の本質は、「人間の脳、そして人工的なネットワークが『学習する』という現象を、いかにして厳密な数学の言葉で記述するか」にありました。
彼が提唱した数々の理論は、現在のLLM(大規模言語モデル)やCNN(畳み込みニューラルネットワーク)のバックボーンそのものを形作っています。
独創の極み:確率の空間を視覚化する「情報幾何学」とは何か
甘利俊一氏の最大の業績であり、世界中の数学者・AI研究者を今なお驚嘆させているのが「情報幾何学(Information Geometry)」の創始です。
通常の幾何学(ユークリッド幾何学など)は、私たちが暮らす3次元空間や、物体の形を対象とします。一方で甘利氏は、「確率分布が並ぶ空間」にも曲がった広がり(多様体)があり、そこにも幾何学的な構造が存在することを見出しました。
| 【技術的ブレイクスルー:自然勾配法(Natural Gradient Descent)】 AIの学習プロセスにおいて、一般的に損失関数を最小化するために「勾配降下法」が使われます。しかし、通常の勾配降下法は、パラメータ空間の「見かけの距離」に依存するため、パラメータの表現方法が変わると最適化の挙動が不安定になるという致命的な弱点を持っています。 甘利氏は情報幾何学を応用し、確率分布の真の距離(KLダイバージェンス)に基づいた不変な勾配である「自然勾配」を導き出しました。 |
ここで G(θ) はフィッシャー情報行列であり、確率空間の歪みを補正する「リーマン計量」の役割を果たします。この自然勾配法は、現在の高度な深層学習アルゴリズム(例えば、自然言語処理の最適化や強化学習のPPOなど)の基盤、あるいは発想の源流として決定的な影響を与えています。
誤差逆伝播法の「前夜」を創った男
ディープラーニングのブレイクスルーを語る上で欠かせない「誤差逆伝播法(バックプロパゲーション)」。これが1980年代にデビッド・ラメルハートらによって
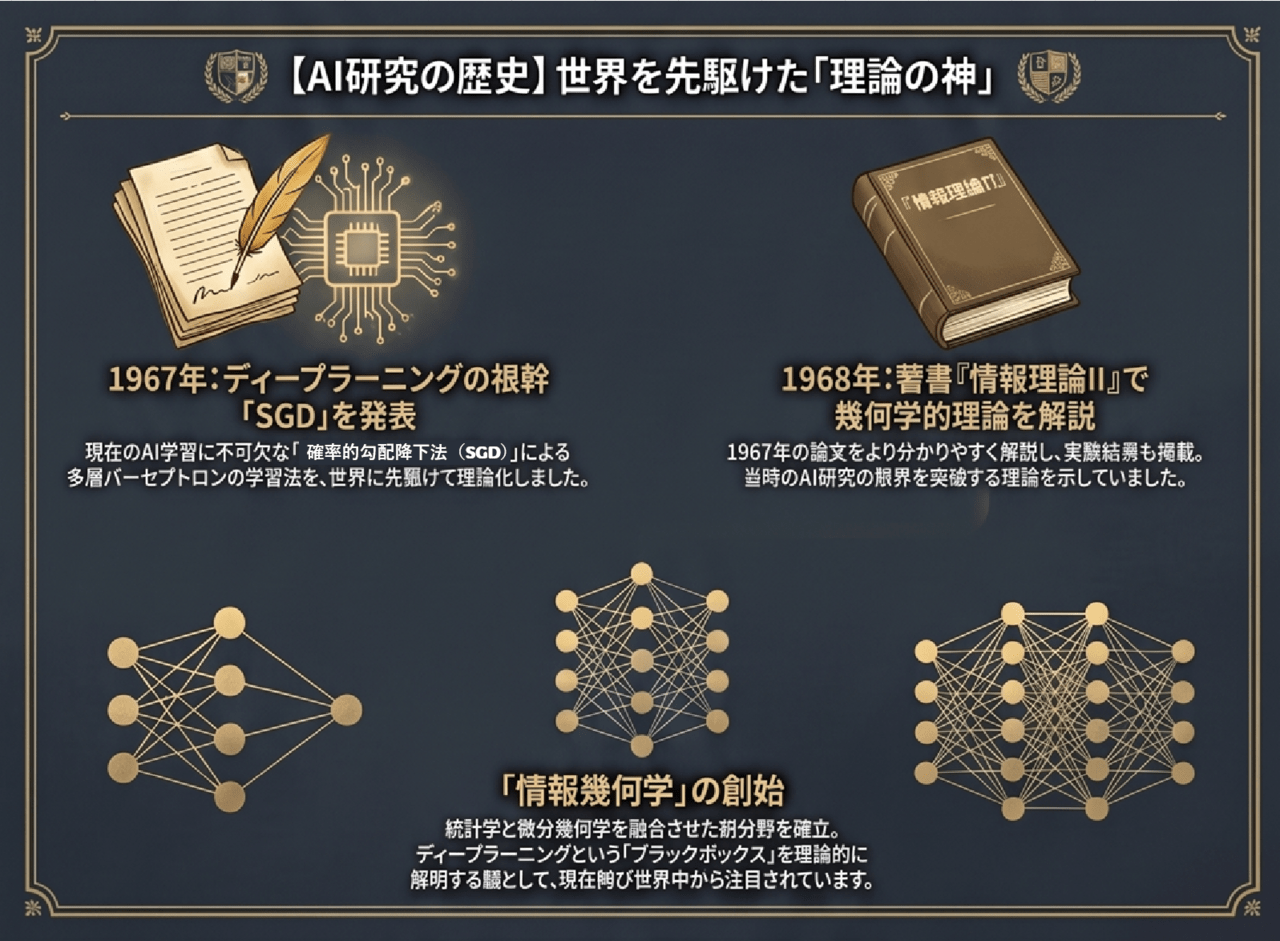
広く普及するより遥か前、1967年の時点で甘利氏は「多層パーセプトロンの学習アルゴリズム」に関する論文を発表していました。
当時の計算資源の限界や、AIの冬の時代(第1次・第2次AIブームの終焉) によって一時的に埋もれた形にはなったものの、数理的な正しさは不変です。
甘利氏の数理モデルは、「ニューラルネットワークは層を重ねることで、自律的に特徴量を獲得できる」という深層学習の本質を、すでに予見していたのです。
機械学習から「深層学習(ディープラーニング)」への決定的なパラダイムシフト
ここで、従来の「機械学習」と、甘利氏の思想の延長線上にある現代の「深層学習」の違いを技術的に整理しておきましょう。
| 要素 | 従来の機械学習(Feature Engineering型) | 現代の深層学習(End-to-End型) |
| 特徴量の抽出 | 人間がドメイン知識を基に設計(職人芸) | データからネットワークが自律的に自動抽出 |
| 表現能力 | 線形・単純な非線形に限定されやすい | 超多層(ディープ)構造による高度な非線形表現 |
| 数理的ダイナミクス | 局所最適解に陥りにくいが限界がある | 高次元の損失関数空間(鞍点)を滑らかに降下 |
従来の機械学習は、人間が「どこに注目すべきか(特徴量)」を指示しなければなりませんでした。しかし、深層学習は、甘利氏が数理的に証明しようとした
「高次元空間のダイナミクス」そのものを利用し、生データ(raw data)から自律的にその本質(DNA)を規定するパターンを学習します。
この性質が、AIの応用範囲を爆発的に広げることになりました。
数理の結晶が導く終着点:サイバーセキュリティの概念を変革する
甘利俊一氏が拓いた、ニューラルネットワークによる「自律的な特徴量(本質)の抽出」という深層学習のテクノロジー。
これが今、最も劇的な効果を発揮している領域があります。それこそが、巧妙化・高難度化を極めるサイバーセキュリティの世界です。
従来のセキュリティ対策(EPP/EDR)は、既知のマルウェアの「シグネチャ(定義ファイル)」とのパターンマッチングや、人間が定義したルールベースの
「機械学習」に依存していました。しかし、攻撃者がAIを駆使して毎秒のように亜種やゼロデイ(未知の脆弱性)攻撃を仕掛けてくる現代において、
人間が定義したルールは一瞬で陳腐化します。
そこで登場したのが、世界で初めてディープラーニングをサイバーセキュリティに全面適用した革新的なエンドポイントセキュリティソリューション
「Deep Instinct(ディープインスティンクト)」なのです。
なぜ「Deep Instinct」は圧倒的なのか?
- 人間を排除した「真の自律学習」:従来の機械学習セキュリティ製品のように「人間が設計した特徴量」に依存しません。数億におよぶ悪意あるファイルと安全なファイルのraw データを深層学習エンジン「Deep Instinct Deep Learning Core」に投入し、マルウェアの「DNA」とも言える本質的な構造パターンを自律的に学習しています。凄いのは1日に数億という構造パターンを独自ラボでNVIDIAのGPUを使い演算処理にて自己学習しているというから凄まじい・・
- 驚異的な先制防御(予測して防ぐ):独自の学習モデル「D-Brain」を軽量な予測モデルとしてエンドポイントに配布。これにより、新種・亜種、ランサムウェア、ゼロデイ攻撃といった「これまで世界に存在しなかった未知の脅威」を、実行される前(着弾した瞬間の20ミリ秒未満)に予測し、リアルタイムに検知・隔離します。
- 「アラート疲れ」からの解放:誤検知率は驚異の「1%未満」。EDRのように「侵入された後の事後対応」で大量のアラートに追われる運用負荷(アラート疲れ)を根本から解消し、運用の平穏を取り戻します。
- 完全オフラインでも機能する数理の力:ネットワーク接続を前提とせず、端末内に組み込まれた数理モデル(D-Brain)単体で自律的に脅威を判定するため、工場や閉域網, あるいは移動中のPCでも完全に保護されます。
まとめ:レジェンドの知恵を、ビジネスの最前線の盾に
甘利俊一氏が半世紀前に蒔いた「ニューラルネットワークの数理」という種は、時代を超え、理論から実用へと昇華し、今や企業のデジタル資産を守る最強の盾「Deep Instinct」として結実しました。「侵入される前提の対策(EDR)」に莫大なコストと人的リソースを割き続ける時代は、終わりを告げようとしています。
さあそろそろ深層学習がもたらす「予防ファースト」の衝撃を、あなたのビジネスインフラにも取り入れてみてませんか。 ※SCSKではPoVも提供しています。
■ディープラーニングによる予防型エンドポイントセキュリティに興味をお持ちの方へ
本記事でご紹介したディープラーニング(深層学習)による革新的な防御思想を、実際のプロダクトとして体現し、
多くのお客様の環境を守っているのが、SCSKが取り扱う「Deep Instinct(ディープインスティンクト)」です。
従来のセキュリティ運用(EDRなど)に限界を感じている方、未知のランサムウェア対策を強化したい方は、ぜひ以下の製品詳細ページをご覧ください。
